On Fri, 2/14/2025 12:47 AM, Boris wrote:
I understand that HDDs can have mechanical failures, but when SSDs came on the scene, I wondered how it is that SSDs 'wear' out. I've got many
machines with HDDs (one is a 20 year old XP box, still working fine) and
some with SSDs, none of which have failed. I've also got many external
HDDs, all still good.
Anyway, I've always heard that SSDs can wear out after many writes. I started to read about the physical construction of SSDs, but I ended going down the rabbit hole, reading about wear leveling and, of course trim, but never found anything about *why* a SSD 'wears' out.
How does a SSD wear out? And while I'm asking, does the same 'wearing' out occur happen on a USB flash drive?
Thanks.
The physical cells, the structure at the atomic level, is
damaged by the writes.
Each cell has a "voltage" stored on it. Established by putting
some electrons on a floating gate. The path for this is
quantum mechanically disallowed, and to get the electrons
onto the gate requires tunneling. The electrons will sit
on the gate for up to ten years (retention time estimate, info
on this has not been updated in a long long time so we are left
to guess whether it scales in any way with gate size).
Imagine a capacitor, charged to any voltage between 0.000V and 1.000V.
If we divide the cell voltage into "ranges of voltage", we can
associate values with the voltage. 0.125V = 001, 0.250V = 010, 0.375V = 011
and so on. This requires some fairly careful charging. By dividing
the voltages like this, there isn't a lot of noise margin.
The cell voltage is passed to an analog comparator. It defines a
"window of voltages" for which 001 is the interpretation, another
"window of voltages" for which 010 is the interpretation.
In this way, we can store multiple bits per cell (three bits in the
example given so far, or TLC). Notice though, that the more "bits"
we pretend to store in each cell, the voltage ranges are getting
smaller and smaller. Our greedy stuffing of bits like this,
shortens the estimated drive life.
If there is any threshold shift in the cell as it ages,
then the voltages could be thrown off. This causes an
equivalent "bit corruption", when the interpreted voltage is incorrect.
Back when flash storage devices had one bit per cell (SLC),
the noise margins were very good. You could write the cell
100,000 times, and the voltage value was always interpreted
correctly. Any voltage over 0.500V was a logic 1, any
voltage less than 0.500V was a logic 0.
But we could not be happy with our (mostly bulletproof) discovery.
We insisted on density over integrity. Thus the TLC and QLC
SSDs of today, stuff more bits per cell, and the corrected
value (taking write amplification into account) is 600 writes per cell.
Which is a large drop compared to the SLC value of 100,000 writes per cell.
A 1TB drive may have a rating of 600TBW. That amounts to writing
the drive 600 times, end to end. If you buy a 2TB drive, the rating
is 1200TBW, which is still 600 writes of 2TB each time. SSDs are
like toilet paper, they are a consumable item, they wear out.
OK, so let's try to use our shiny new SSD. Everyone likes to write
sector 0 (the MBR). Perhaps it receives more writes than the other
sectors. Before I know it, the MBR has been written 600 times.
Yet, my copy of shell32.dll has only been written 1 time. Our SSD
got "wore out" by abusing only one of the sectors. That's not very good. without some clever scheme, you can "burn a hole" in the SSD.
We had to fix that.
By mapping the sectors, using a mapping table, and "moving the MBR around
each time it is written", that is wear leveling. The drive has a pool of unwritten blocks. On a write request, an unused block is written.
Perhaps the block is at address 27, and it contained MBR sector 0.
The map file the drive keeps then, it has to remember that aspect.
On a read, we request sector 0, the map goes "oh, that is block 27",
and the drive does the read at that address, and there is our MBR.
Now, if I abuse the MBR by writing it a lot, a hole isn't burned in it.
The sector has been "virtualized", and only the mapping table knows
where my sector is stored :-)
When you TRIM a drive, that exchanges usage information with the drive.
You tell the drive, "at the current time, there is nothing at
address 27, so you can put it in your spare pile". This can improve
the write speed of the drive, as it has more bulk material when
it does housekeeping inside, and rearranges your data (under the
direction of the edited map table). If you ask for a sector (white space)
that has been moved into the free pool pile, then zeros are substituted.
*This has an impact on your UnErase capability with Recuva.* If
you erase a file by mistake, do a TRIM, then the erased file,
the clusters are "gone". But other than that side effect, the TRIM
is an attempt to give the SSD a "hint" as to which areas of the
drive don't really need storage, because they are white space
on the partition and no "used clusters" are stored there.
What is the end result of all this ? Well, at the end of life,
you could have written the MBR *thousands* of times and it does
not matter. The statistics of the free pool usage, and the re-circulation
of the blocks, means that one block is written 599 times,
another block 600 times, a third block 601 times, but the blocks
have been worn equally with pretty low spread between blocks.
The "wear" on the cells, has been equalized by the wear leveling schemes.
It also means, if you pop a flash chip out of the drive, and read
it sequentially with your lab reader device, the data is "scrambled"
and almost unreadable. Unless the technician can find the map file, the
data is spread all over the place.
A USB flash stick doesn't do this. A USB flash stick with TLC cells in
it, wears out in no time. A USB flash stick with SLC cells, it just
goes and goes, seemingly forever.
Whereas, via a lot of whizzy tech, the SSD is an observably more reliable device,
and via watching the wear life field in the SMART table, you can
tell how many years remain on the drive. You can write the MBR a
thousand times right now, and the predicted life of the drive does
not change all that much. It's still "99% good". Whereas if you did
that to the USB stick you bought from Walmart, now it is dead (because
the MBR can't be used any more).
There is atomic level damage to the structure of the cell, on writes.
The level of damage is temperature dependent. The predicted
charge retention time on a write is also temperature dependent.
Scientists noticed this in the lab, that there was less damage
at elevated temperature. They figured out, if we could "anneal"
the drive after some period of usage, the cells would be almost
brand new in terms of structural damage. But nobody has figured
out a way to make individual cells "anneal" on command. And I think
the temperature required for this, might be slightly out of range
for the materials used in the drive. The annealing remains as a
lab curiosity.
Generally speaking, all storage devices like to know their
temperature, during a write. The controls at the point of writing,
may need to be "temperature compensated". A hard drive makes some
adjustment, if the housing is running at high temperature.
An SSD may be doing the same sort of thing.
If we were willing to accept a drop in drive capacity, then we
would no longer need to be staring at the SMART table all the time.
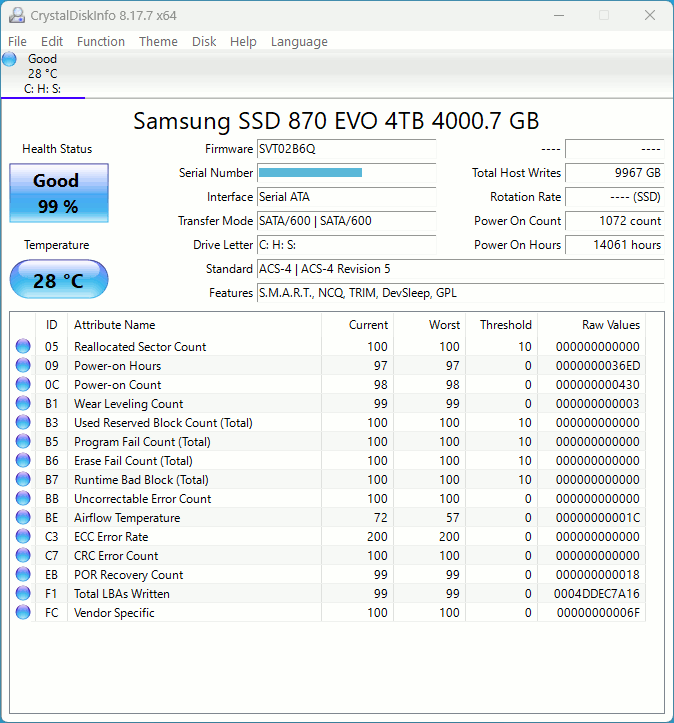
[Picture] the SMART table of my SSD drive right now...
https://i.postimg.cc/rsxhfq4x/crystal-daily-driver-4-TBSSD.gif
Notice that my drive has been running for 14,000 hours, and it is
at 99% good. That means, based on averages, it might last to 1,400,000 hours
at the current rate of usage.
If I were a video editor, editing raw video (200GB per vid), and saving
those out multiple times a day, I would go through that drive in no
time. One of the reasons the usage is so low on that drive, is I use
my RAMDisk for a lot of stuff, and the SSD does not get the wear.
Some of my VMs, the container gets transferred to the RAMDisk,
I do some stuff, I throw the container away at the end of the session.
Thus, my usage is not an indication of what your usage will be.
One partition, it gets to store those pictures above. So that partition
is contributing to the wear of the device. That, and Windows Defender
scans (which write out some sort of status).
In terms of backup policy then, I won't have to worry for a number
of years, about the life of the drive. However, if the drive has
a "heart failure", like if the map file got trashed or some other
metadata table got trashed, maybe the next day, the drive would not
detect and I could not boot. While that outcome is obscure, there
have been cases of my drive taking a dump like that. And that is
why we still need backups (preferably on a cheap and large hard drive).
Back in the OCZ era (first generation SSDs), heart failures were more
common, and this had to do with the quality of the firmware the drive
runs inside. The drive has processor cores, multiple of them, and
the firmware the drive runs, has to juggle the map file without losing it.
On one occasion, when Intel was entering the SSD business, their
firmware people took one look at samples of code written, and they
were not at all happy about the firmware qualities. Intel then rewrote
the firmware for their drive, and did not copy anyone elses firmware
(via buying the firmware along with the controller chip used). There was
a general industry silence after this event, but my presumption is,
that information made the rounds in the industry, about what sort of
tricks were needed to improve on loss of metadata and so on.
What the drive is doing, is tricky. It must have atomic updates,
some sort of journal inside. It must have all sorts of protections
inside, to protect it on a power fail. The drives don't use a
Supercap for emergency power. Some of the drives don't even have
DRAM for the map file storage (HMB Host Managed Buffer drives).
The ball juggling going on inside the drive is perilous. Yet,
my drive has had a few power fails, without disappearing on me :-)
Enjoy!
Paul
--- SoupGate-Win32 v1.05
* Origin: fsxNet Usenet Gateway (21:1/5)
{kind=link}