No, it does /not/. That's the /whole/ point of #embed, and the main motivation for its existence. People have always managed to embed
binary source files into their binary output files - using linker
tricks, or using xxd or other tools (common or specialised) to turn
binary files into initialisers for constant arrays (or structs).
I've done so myself on many projects, all integrated together in
makefiles.
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
No, it does /not/. That's the /whole/ point of #embed, and the main
motivation for its existence. People have always managed to embed
binary source files into their binary output files - using linker
tricks, or using xxd or other tools (common or specialised) to turn
binary files into initialisers for constant arrays (or structs).
I've done so myself on many projects, all integrated together in
makefiles.
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
/c/altera/13.0sp1/quartus/bin64/db_wys.dll is 52 MB file
$ time xxd -i < /c/altera/13.0sp1/quartus/bin64/db_wys.dll > xxd.txt
real 0m15.288s
user 0m15.054s
sys 0m0.187s
$ time ../quick_xxd/bin_to_list1
/c/altera/13.0sp1/quartus/bin64/db_wys.dll > bin_to_list1.txt
real 0m8.502s
user 0m0.000s
sys 0m0.000s
$ time ../quick_xxd/bin_to_list
/c/altera/13.0sp1/quartus/bin64/db_wys.dll > bin_to_list.txt
real 0m1.326s
user 0m0.000s
sys 0m0.000s
bin_to_list probably limited by write speed of SSD that in this
particular case is ~9 y.o. and was used rather intensively during these years.
bin_to_list1 is DYI written in ~5 min.
bin_to_list is DYI written in ~55 min.
In post above David Brown mentioned 'other tools (common or
specialised)'. I'd like to know what they are and how fast they are.
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
No, it does /not/. That's the /whole/ point of #embed, and the main
motivation for its existence. People have always managed to embed
binary source files into their binary output files - using linker
tricks, or using xxd or other tools (common or specialised) to turn
binary files into initialisers for constant arrays (or structs).
I've done so myself on many projects, all integrated together in
makefiles.
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
No, it does /not/. That's the /whole/ point of #embed, and the main
motivation for its existence. People have always managed to embed
binary source files into their binary output files - using linker
tricks, or using xxd or other tools (common or specialised) to turn
binary files into initialisers for constant arrays (or structs).
I've done so myself on many projects, all integrated together in
makefiles.
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
/c/altera/13.0sp1/quartus/bin64/db_wys.dll is 52 MB file
$ time xxd -i < /c/altera/13.0sp1/quartus/bin64/db_wys.dll > xxd.txt
real 0m15.288s
user 0m15.054s
sys 0m0.187s
$ time ../quick_xxd/bin_to_list1
/c/altera/13.0sp1/quartus/bin64/db_wys.dll > bin_to_list1.txt
real 0m8.502s
user 0m0.000s
sys 0m0.000s
$ time ../quick_xxd/bin_to_list
/c/altera/13.0sp1/quartus/bin64/db_wys.dll > bin_to_list.txt
real 0m1.326s
user 0m0.000s
sys 0m0.000s
bin_to_list probably limited by write speed of SSD that in this
particular case is ~9 y.o. and was used rather intensively during these
years.
bin_to_list1 is DYI written in ~5 min.
bin_to_list is DYI written in ~55 min.
In post above David Brown mentioned 'other tools (common or
specialised)'. I'd like to know what they are and how fast they are.
I think you might be missing the point here.
The start point is a possibly large binary data file.
The end point is to end up with an application whose binary code has
embedded that data file. (And which makes that data available inside the
C program as a C data structure.)
Without #embed, one technique (which I've only learnt about this week)
is to use a tool called 'xxd' to turn that binary file into C source
code which contains an initialised array or whatever.
But, that isn't the bottleneck. You run that conversion once (or
whenever the binary changes), and use the same resulting C code time you build the application. And quite likely, the makefile recognises you
don't need to compile it anyway.
It is that building process that can be slow if that C source describing
the data is large.
That is what #embed helps to address. At least, if it takes the fast
path that has been discussed. But implemented naively, or the fast path
is not viable, then it can be just as slow as compiling that
xxd-generated C.
It will at least however have eliminated that xxd step.
The only translation going on here might be:
* Expanding a binary file to text, or tokens (if #embed is done poorly)
* Parsing that text or tokens into the compiler's internal rep
But all that is happening inside the compiler.
It might be that when xxd /is/ used, there might be a faster program to
do the same thing, but I've not heard anyone say xxd's speed is a
problem, only that it's a nuisance to do.
On Tue, 28 May 2024 15:06:40 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
I think you might be missing the point here.
I don't think so.
I understand your points and agree with just about everything. My post
was off topic, intentionally so.
If we talk about practicalities, the problems with xxd, if there are
problems at all, are not its speed, but the size of the text file
it produces (~6x the size of original binary) and its availability.
I don't know to which package it belongs in typical Linux or BSD distributions, but at least on Windows/msys2 it is part of Vim - rather
big package for which, apart from xxd, I have no use at all.
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
I think you might be missing the point here.
On Debian, xxd is in a package called "xxd" which contains just xxd
and directly associated files (like man pages).
On Tue, 28 May 2024 15:06:40 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
I think you might be missing the point here.
I don't think so.
I understand your points and agree with just about everything. My post
was off topic, intentionally so.
If we talk about practicalities, the problems with xxd, if there are
problems at all, are not its speed, but the size of the text file
it produces (~6x the size of original binary) and its availability.
I don't know to which package it belongs in typical Linux or BSD distributions, but at least on Windows/msys2 it is part of Vim - rather
big package for which, apart from xxd, I have no use at all.
On 28/05/2024 16:56, Michael S wrote:
On Tue, 28 May 2024 15:06:40 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
I think you might be missing the point here.
I don't think so.
I understand your points and agree with just about everything. My
post was off topic, intentionally so.
If we talk about practicalities, the problems with xxd, if there are problems at all, are not its speed, but the size of the text file
it produces (~6x the size of original binary) and its availability.
I don't know to which package it belongs in typical Linux or BSD distributions, but at least on Windows/msys2 it is part of Vim -
rather big package for which, apart from xxd, I have no use at all.
OK, I had go with your program. I used a random data file of exactly
100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
I then tried a simple program in my language, which took 10 seconds.
I looked more closely at yours, and saw you used a clever method of a
table of precalculated stringified numbers.
Using a similar table, plus more direct string handling, the fastest
timing on mine was 3.1 seconds, with 21 numbers per line. (The 21 was supposed to match your layout, but that turned out to be variable.)
Both programs have a trailing comma on the last number, which may be problematical, but also not hard to fix.
I then tried xxd under WSL, and that took 28 seconds, real time, with
a much larger output (616KB instead of 366KB).
But it's using fixed
width columns of hex, complete with a '0x' prefix.
Below is that program but in my language. I tried transpiling to C,
hoping it might be even faster, but it got slower (4.5 seconds with
gcc-O3). I don't know why. It would need manual porting to C.
This hardcodes the input filename. 'readfile' is a function in my
library.
--------------------------------
[0:256]ichar numtable
[0:256]int numlengths
proc main=
ref byte data
[256]char str
const perline=21
int m, n, slen
byte bb
ichar s, p
for i in 0..255 do
numtable[i] := strdup(strint(i))
numlengths[i] := strlen(numtable[i])
od
data := readfile("/c/data100")
n := rfsize
while n do
m := min(n, perline)
n- := m
p := &str[1]
to m do
bb := data++^
s := numtable[bb]
slen := numlengths[bb]
to slen do
p++^ := s++^
od
p++^ := ','
od
p^ := 0
println str
od
end
Also, I think that random numbers are close to worst case for branch predictor / loop length predictor in my inner loop.
Were I thinking about random case upfront, I'd code an inner loop differently. I'd always copy 4 octets (comma would be stored in the
same table). After that I would update outptr by length taken from
additional table, similarly, but not identically to your method below.
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of exactly
100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging SSD
on my test machine and ALOT slower than SSD of David Brown.
I then tried a simple program in my language, which took 10 seconds.
I looked more closely at yours, and saw you used a clever method of a
table of precalculated stringified numbers.
Using a similar table, plus more direct string handling, the fastest
timing on mine was 3.1 seconds, with 21 numbers per line. (The 21 was
supposed to match your layout, but that turned out to be variable.)
Yes, I try to get line length almost fixed (77 to 80 characters) and
make no attempts to control number of entries per line.
Since you used random generator, a density advantage of my approach is smaller than in more typical situations, where 2-digit numbers are more common than 3-digit numbers.
Also, I think that random numbers are close to worst case for branch predictor / loop length predictor in my inner loop.
Were I thinking about random case upfront, I'd code an inner loop differently. I'd always copy 4 octets (comma would be stored in the same table). After that I would update outptr by length taken from
additional table, similarly, but not identically to your method below.
There exist files that have near-random distribution, e.g. anything
zipped or anything encrypted, but I would think that we rarely want
them embedded.
This hardcodes the input filename. 'readfile' is a function in my
library.
--------------------------------
[0:256]ichar numtable
[0:256]int numlengths
proc main=
ref byte data
[256]char str
const perline=21
int m, n, slen
byte bb
ichar s, p
for i in 0..255 do
numtable[i] := strdup(strint(i))
numlengths[i] := strlen(numtable[i])
od
data := readfile("/c/data100")
Reading whole file upfront is undoubtly faster than interleaving of
reads and writes. But by my set of unwritten rules that I imposed on
myself, it is cheating.
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
My machine uses an SSD.
However the tests were run on Windows, so I ran your program again
under WSL; now it took 14 seconds (using both gcc-O3 and gcc-O2).
On Tue, 28 May 2024 19:57:38 +0100
OK, I had go with your program. I used a random data file of exactly
100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging SSD
on my test machine and ALOT slower than SSD of David Brown.
On Tue, 28 May 2024 23:23:15 +0300
Michael S <already5chosen@yahoo.com> wrote:
Also, I think that random numbers are close to worst case for branch
predictor / loop length predictor in my inner loop.
Were I thinking about random case upfront, I'd code an inner loop
differently. I'd always copy 4 octets (comma would be stored in the
same table). After that I would update outptr by length taken from
additional table, similarly, but not identically to your method below.
That's what I had in mind:
unsigned char bin2dec[256][MAX_CHAR_PER_NUM+1]; //
bin2dec[MAX_CHAR_PER_NUM] => length for (int i = 0; i < 256;++i) {
On 28/05/2024 22:45, Michael S wrote:
On Tue, 28 May 2024 23:23:15 +0300
Michael S <already5chosen@yahoo.com> wrote:
Also, I think that random numbers are close to worst case for
branch predictor / loop length predictor in my inner loop.
Were I thinking about random case upfront, I'd code an inner loop
differently. I'd always copy 4 octets (comma would be stored in the
same table). After that I would update outptr by length taken from
additional table, similarly, but not identically to your method
below.
That's what I had in mind:
unsigned char bin2dec[256][MAX_CHAR_PER_NUM+1]; //
bin2dec[MAX_CHAR_PER_NUM] => length for (int i = 0; i < 256;++i)
{
Is this a comment that has wrapped?
After fixing a few such line breaks, this runs at 3.6 seconds
compared with 4.1 seconds for the original.
Although I don't quite understand the comments about branch
prediction.
I think runtime is still primarily spent in I/O.
If I take the 1.9 second version, and remove the fwrite, then it runs
in 0.8 seconds. 0.7 of that is generating the text (366MB's worth, a
line at a time).
In my language that part takes 0.9 seconds, which is a more typical difference due to gcc's superior optimiser.
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
OK, I had go with your program. I used a random data file of exactly
100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging SSD
on my test machine and ALOT slower than SSD of David Brown.
David Brown's machines are always faster than anyone else's.
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 16:56, Michael S wrote:
On Tue, 28 May 2024 15:06:40 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 12:41, Michael S wrote:
On Sun, 26 May 2024 13:09:36 +0200
David Brown <david.brown@hesbynett.no> wrote:
I think you might be missing the point here.
I don't think so.
I understand your points and agree with just about everything. My
post was off topic, intentionally so.
If we talk about practicalities, the problems with xxd, if there are
problems at all, are not its speed, but the size of the text file
it produces (~6x the size of original binary) and its availability.
I don't know to which package it belongs in typical Linux or BSD
distributions, but at least on Windows/msys2 it is part of Vim -
rather big package for which, apart from xxd, I have no use at all.
OK, I had go with your program. I used a random data file of exactly
100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging SSD
on my test machine and ALOT slower than SSD of David Brown.
I then tried a simple program in my language, which took 10 seconds.
I looked more closely at yours, and saw you used a clever method of a
table of precalculated stringified numbers.
Using a similar table, plus more direct string handling, the fastest
timing on mine was 3.1 seconds, with 21 numbers per line. (The 21 was
supposed to match your layout, but that turned out to be variable.)
Yes, I try to get line length almost fixed (77 to 80 characters) and
make no attempts to control number of entries per line.
Since you used random generator, a density advantage of my approach is smaller than in more typical situations, where 2-digit numbers are more common than 3-digit numbers.
Also, I think that random numbers are close to worst case for branch predictor / loop length predictor in my inner loop.
Were I thinking about random case upfront, I'd code an inner loop differently. I'd always copy 4 octets (comma would be stored in the same table). After that I would update outptr by length taken from
additional table, similarly, but not identically to your method below.
There exist files that have near-random distribution, e.g. anything
zipped or anything encrypted, but I would think that we rarely want
them embedded.
Both programs have a trailing comma on the last number, which may be
problematical, but also not hard to fix.
I don't see where (in C) it could be a problem. On the other hand, I can imagine situations where absence of trailing comma is inconvinient.
Now, if your language borrow its array initialization syntax from
Pascal then trailing commas are indeed undesirable.
I then tried xxd under WSL, and that took 28 seconds, real time, with
a much larger output (616KB instead of 366KB).
616 MB, I suppose.
Timing is very similar to my measurements. It is obvious that in case
of xxd, unlike in the rest of our cases, the bottleneck is in CPU rather
than in HD.
But it's using fixed
width columns of hex, complete with a '0x' prefix.
Below is that program but in my language. I tried transpiling to C,
hoping it might be even faster, but it got slower (4.5 seconds with
gcc-O3). I don't know why. It would need manual porting to C.
Why do you measure with gcc -O3 instead of more robust and more popular
-O2 ? Not that it matters in this particular case, but in general I
don't think that it is a good idea.
Reading whole file upfront is undoubtly faster than interleaving of
reads and writes. But by my set of unwritten rules that I imposed on
myself, it is cheating.
On Wed, 29 May 2024 01:29:00 +0100
bart <bc@freeuk.com> wrote:
I think runtime is still primarily spent in I/O.
That's undoubtedly correct.
On 29/05/2024 01:54, bart wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
David Brown's machines are always faster than anyone else's.
That seems /highly/ unlikely. Admittedly the machine I tested on is
fairly new - less than a year old. But it's a little NUC-style
machine at around the $1000 price range, with a laptop processor.
The only thing exciting about it is 64 GB ram (I like to run a lot of
things at the same time in different workspaces).
But I am better than some people at getting my machines to run
programs efficiently. I don't use Windows for such things (I happily
run Windows on a different machine for other purposes), and I
certainly don't use layers of OS or filesystem emulation such as WSL
and expect code to run at maximal speed.
And as I said in an earlier post, I didn't have the files on any kind
of disk or SSD at all - they were all in a tmpfs filesystem to
eliminate that bottleneck.
I suspect that your system just has a much faster fgetc
implementation. How long does an fgetc() loop over a 100MB input take
on your machine?
On mine it's about 2 seconds on Windows, and 3.7 seconds on WSL.
Using DMC, it's 0.65 seconds.
On Wed, 29 May 2024 10:32:29 +0200
David Brown <david.brown@hesbynett.no> wrote:
On 29/05/2024 01:54, bart wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
David Brown's machines are always faster than anyone else's.
That seems /highly/ unlikely. Admittedly the machine I tested on is
fairly new - less than a year old. But it's a little NUC-style
machine at around the $1000 price range, with a laptop processor.
The only thing exciting about it is 64 GB ram (I like to run a lot of
things at the same time in different workspaces).
Modern laptop processors with adequate cooling can be as fast as
desktop (and faster than server) for a task that uses only 1 or 2
cores. Especially when no heavy vector math involved. If the task runs
only for few seconds, like in our tests, then they CPU can be fast even without good cooling.
And $1000 is not exactly low price for mini-PC without display. Last
time I bought one for my mother, it costed ~$650 including Win11 Home
Ed.
But I am better than some people at getting my machines to run
programs efficiently. I don't use Windows for such things (I happily
run Windows on a different machine for other purposes), and I
certainly don't use layers of OS or filesystem emulation such as WSL
and expect code to run at maximal speed.
WSL would not affect user-level CPU-bound part and even majority of kernel-level CPU-bound parts. It can slow down I/O, yes. But it turned
out (see my post above) that the bottleneck was in CPU.
And as I said in an earlier post, I didn't have the files on any kind
of disk or SSD at all - they were all in a tmpfs filesystem to
eliminate that bottleneck.
You should have said it yesterday.
On Wed, 29 May 2024 00:54:23 +0100
bart <bc@freeuk.com> wrote:
I suspect that your system just has a much faster fgetc
implementation. How long does an fgetc() loop over a 100MB input take
on your machine?
On mine it's about 2 seconds on Windows, and 3.7 seconds on WSL.
Using DMC, it's 0.65 seconds.
Your suspicion proved incorrect, but it turned out to be pretty good question!
$ time ../quick_xxd/getc_test.exe uu.txt
193426754 byte. xor sum 1.
real 0m3.604s
user 0m0.000s
sys 0m0.000s
52 MB/s. Very very slow!
So, may be, fgetc() is not at fault? May be, its OS and the crap that
the corporate IT adds on top of the OS?
Let's test this hipothesys.
$ time ../quick_xxd/fread_test.exe uu.txt
193426754 byte. xor sum 1.
real 0m0.094s
user 0m0.000s
sys 0m0.000s
So, let's rewrite our tiny app with fread().
real 0m0.577s
user 0m0.000s
sys 0m0.000s
152.8 MB/s. That's much better. Some people would even say that it is
good enough.
Two hours later it turned out to be completely incorrect. That is, thetime was spent in routine related to I/O, but in the 'soft' part of it
I think runtime is still primarily spent in I/O.
I did. I mentioned it in my post comparing the timings of xxd, your
program, and some extremely simple Python code giving the same
outputs.
but I muliple times
struggled with ifstream and ofstream in terms of performance.
On 29/05/2024 10:38, Michael S wrote:
On Wed, 29 May 2024 00:54:23 +0100
bart <bc@freeuk.com> wrote:
I suspect that your system just has a much faster fgetc
implementation. How long does an fgetc() loop over a 100MB input
take on your machine?
On mine it's about 2 seconds on Windows, and 3.7 seconds on WSL.
Using DMC, it's 0.65 seconds.
Your suspicion proved incorrect, but it turned out to be pretty good question!
$ time ../quick_xxd/getc_test.exe uu.txt
193426754 byte. xor sum 1.
real 0m3.604s
user 0m0.000s
sys 0m0.000s
52 MB/s. Very very slow!
I got these results for a 100MB input. All are optimised where
possible:
mcc 1.9 seconds
gcc 1.9
tcc 1.95
lccwin32 0.7
DMC 0.7
The first three likely just use fgetc from msvcrt.dll. The other two
probably use their own libraries.
So, may be, fgetc() is not at fault? May be, its OS and the crap
that the corporate IT adds on top of the OS?
Let's test this hipothesys.
$ time ../quick_xxd/fread_test.exe uu.txt
193426754 byte. xor sum 1.
real 0m0.094s
user 0m0.000s
sys 0m0.000s
I get these results:
mcc 0.25 seconds
gcc 0.25
tcc 0.35
lccwin32 0.35
DMC 0.3
All are repeated runs of the same file, so all timings likely used
cached version of the data file.
Most of my tests assume that since (1) I don't know how to to do a
'cold' load without restarting my machines; (2) in real applications
such as compilers the same files are repeatedly processed anyway, eg.
you're compiling the file you've just edited, or just downloaded, or
just copied...
So, let's rewrite our tiny app with fread().
real 0m0.577s
user 0m0.000s
sys 0m0.000s
152.8 MB/s. That's much better. Some people would even say that it
is good enough.
I now get:
mcc 2.3 seconds
gcc 1.6
tcc 2.3
lccwin32 2.9
DMC 2.9
You might remember that the last revised version of your test,
compiled with gcc, took 3.6 seconds, of which 2 seconds was reading
the file a byte at a time took 2 seconds.
By using a 128KB buffer, you get most of the benefits of reading the
whole file at once
(it just lacks the simplicity).
So nearly all of that 2 seconds is saved.
3.6 - 2.0 is 1.6, pretty much the timing here.
Two hours later it turned out to be completely incorrect. That is,time was spent in routine related to I/O, but in the 'soft' part of it
the
rather than in the I/O itself.
You don't count time spent within file-functions as I/O? To me 'I/O'
is whatever happens the other side of those f* functions, including
whatever poor buffering strategies they could be using.
Because 'fgetc' could also have been implemented using a 128KB buffer
instead of 512 bytes or whatever it uses.
I discovered the poor qualities of fgetc many years ago and generally
avoid it; it seems you've only just realised its problems.
BTW I also tweaked the code in my own-language version of the
benchmark. (I also ported it to C, but that version got accidentally deleted). The fastest timing of this test is now 1.65 seconds.
If I comment out the 'fwrite' call, the timing becomes 0.7 seconds,
of which 50ms is reading in the file, leaving 0.65 seconds.
So the I/O in this case accounts for 1.0 seconds of the 1.65 seconds
runtime, so when I said:
I think runtime is still primarily spent in I/O.
That was actually correct.
If I comment out the 'fwrite' calls in your program, the runtime
reduces to 0.2 seconds, so it is even more correct in that case. Or
is 'fwrite' a 'soft' I/O call too?
On Wed, 29 May 2024 14:10:14 +0200
David Brown <david.brown@hesbynett.no> wrote:
I did. I mentioned it in my post comparing the timings of xxd, your
program, and some extremely simple Python code giving the same
outputs.
Then both me and Bart didn't pay attention to this part of your
yesterday's post. Sorry.
On Wed, 29 May 2024 12:23:51 +0100
bart <bc@freeuk.com> wrote:
So, let's rewrite our tiny app with fread().
real 0m0.577s
user 0m0.000s
sys 0m0.000s
152.8 MB/s. That's much better. Some people would even say that it
is good enough.
I now get:
mcc 2.3 seconds
gcc 1.6
tcc 2.3
lccwin32 2.9
DMC 2.9
Mine was with MSVC from VS2019. gcc on msys2 (ucrt64 variant) should be identical.
I wonder why your results are so much slower than mine.
Slow write speed of SSD or slow CPU?
You might remember that the last revised version of your test,
compiled with gcc, took 3.6 seconds, of which 2 seconds was reading
the file a byte at a time took 2 seconds.
By using a 128KB buffer, you get most of the benefits of reading the
whole file at once
I hope so.
(it just lacks the simplicity).
The simplicity in your case is due to complexity of figuring out the
size of the file and of memory allocation and of handling potential
failure of memory allocation all hidden within run-time library of you > language.
On 29/05/2024 13:23, Michael S wrote:
On Wed, 29 May 2024 12:23:51 +0100
bart <bc@freeuk.com> wrote:
So, let's rewrite our tiny app with fread().
real 0m0.577s
user 0m0.000s
sys 0m0.000s
152.8 MB/s. That's much better. Some people would even say that it
is good enough.
I now get:
mcc 2.3 seconds
gcc 1.6
tcc 2.3
lccwin32 2.9
DMC 2.9
Mine was with MSVC from VS2019. gcc on msys2 (ucrt64 variant)
should be identical.
I wonder why your results are so much slower than mine.
Slow write speed of SSD or slow CPU?
You'd need to isolate i/o from the data processing to determine that.
However, the fastest timing on my machine is 1.4 seconds to read
100MB and write 360MB.
Your timing is 0.6 seconds to read 88MB and write, what, 300MB of
text?
The difference is about 2:1, which is not that unusual given two
different processors, two kinds of storage device, two kinds of OS
(?) and two different compilers.
But remember that a day or two ago, your original program took over 4 seconds, and it now takes 1.6 seconds (some timings are 1.4 seconds,
but I think that's the C port of my code).
(BTW I guess that superimposing your own faster buffer is not
consdered cheating any more!)
You might remember that the last revised version of your test,
compiled with gcc, took 3.6 seconds, of which 2 seconds was reading
the file a byte at a time took 2 seconds.
By using a 128KB buffer, you get most of the benefits of reading
the whole file at once
I hope so.
(it just lacks the simplicity).
The simplicity in your case is due to complexity of figuring out the
size of the file and of memory allocation and of handling potential
failure of memory allocation all hidden within run-time library of
you > language.
Yes, that moves those details out of the way to keep the main body of
the code clean.
Your C code looks chaotic (sorry), and I had quite a few problems in understanding and trying to modify or refactor parts of it.
Below is the main body of my C code. Below that is the main body of
your latest program, not including the special handling for the last
line, that mine doesn't need.
------------------------------------------
while (n) {
m = n;
if (m > perline) m = perline;
n -= m;
p = str;
for (int i = 0; i < m; ++i) {
bb = *data++;
s = numtable[bb];
slen = numlengths[bb];
*p++ = *s;
if (slen > 1)
*p++ = *(s+1);
if (slen > 2)
*p++ = *(s+2);
*p++ = ',';
}
*p++ = '\n';
fwrite(str, 1, p-str, f);
}
------------------------------------------
for (;;) {
enum { BUF_SZ = 128*1024 };
unsigned char inpbuf[BUF_SZ];
size_t len = fread(inpbuf, 1, BUF_SZ, fpin);
for (int i = 0; i < (int)len; ++i) {
unsigned char* dec = bin2dec[inpbuf[i] & 255];
memcpy(outptr, dec, MAX_CHAR_PER_NUM);
outptr += dec[MAX_CHAR_PER_NUM];
if (outptr > &outbuf[ALMOST_FULL_THR]) { // spill output buffer
*outptr++ = '\n';
ptrdiff_t wrlen = fwrite(outbuf, 1, outptr-outbuf, fpout);
if (wrlen != outptr-outbuf) {
err = 2;
break;
}
outptr = outbuf;
}
}
if (err || len != BUF_SZ)
break;
}
------------------------------------------
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons, much
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free. (And I buy these bare-bones. Machines with Windows
"pre-installed" are often cheaper because they are sponsored by the
junk-ware and ad-ware forced on unsuspecting users.)
less tolerant people then their counterparts at another university, but that's another story). And I was given a brand new Windows machine, and
told that we had to use Linux. So I installed a Linux version which ran
on top of Windows. No good, I was told. Might cause problems with that "interesting" set up. So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
On Wed, 29 May 2024 15:16:06 +0100
bart <bc@freeuk.com> wrote:
Your timing is 0.6 seconds to read 88MB and write, what, 300MB of
text?
Much less. Only 193 MB. It seems, this DLL I was textualizing is stuffed
with small numbers. That explains big part of the difference.
I did another test with big 7z archive as an input:
Input size: 116255887
Output size: 425944020
$ time ../quick_xxd/bin_to_listmb /d/bin/tmp.7z uu.txt
real 0m1.170s
user 0m0.000s
sys 0m0.000s
Almost exactly 100 MB/s which is only 1.4-1.6 times faster than your measurements.
Each to his own.
For me your code is unreadable, mostly due to very short names of
variables that give no hint of usage, absence of declarations (I'd
guess, you have them at the top of the function, for me it's no better
than not having them at all) and zero comments.
Besides, our snippets are not functionally identical. Yours don't handle write failures. Practically, on "big" computer it's a reasonable choice, because real I/O problems are unlikely to be detected at fwrite. They
tend to manifest themselves much later. But on comp.lang.c we like to
pretend that life is simpler and more black&white than it is in reality.
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons, much
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free. (And I buy these bare-bones. Machines with Windows
"pre-installed" are often cheaper because they are sponsored by the
junk-ware and ad-ware forced on unsuspecting users.)
less tolerant people then their counterparts at another university, but that's another story). And I was given a brand new Windows machine, and
told that we had to use Linux. So I installed a Linux version which ran
on top of Windows. No good, I was told. Might cause problems with that "interesting" set up. ...
... So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
On 29/05/2024 18:27, Malcolm McLean wrote:
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons,
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free.� (And I buy these bare-bones.� Machines with
Windows "pre-installed" are often cheaper because they are
sponsored by the junk-ware and ad-ware forced on unsuspecting
users.)
much less tolerant people then their counterparts at another
university, but that's another story). And I was given a brand new
Windows machine, and told that we had to use Linux. So I installed
a Linux version which ran on top of Windows. No good, I was told.
Might cause problems with that "interesting" set up. ...
They're quite right in that regard, as I can testify from personal experience.
... So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
Keep in mind that, as David pointed out, the "waste" was probably
negative. You got a better price on the machine than you would have otherwise, and erasing that malware gave you more space to put useful
stuff on your machine.
Below is a version with no declarations at all. It is in a dynamic
scripting language.
It runs in 7.3 seconds (or 6.4 seconds if newlines are dispensed with).
On 28/05/2024 13:41, Michael S wrote:
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
I used 100 MB of random data:
dd if=/dev/urandom bs=1M count=100 of=100MB
I compiled your code with "gcc-11 -O2 -march=native".
I ran everything in a tmpfs filesystem, completely in ram.
xxd took 5.4 seconds - that's the baseline.
Your simple C code took 4.35 seconds. Your second program took 0.9
seconds - a big improvement.
One line of Python code took 8 seconds :
print(", ".join([hex(b) for b in open("100MB", "rb").read()]))
A slightly nicer Python program took 14.3 seconds :
import sys
bs = open(sys.argv[1], "rb").read()
xs = "".join([" 0x%02x," % b for b in bs])
ln = len(xs)
print("\n".join([xs[i : i + 72] for i in range(0, ln, 72)]))
(I have had reason to include a 0.5 MB file in a statically linked
single binary - I'm not sure when you'd need very fast handling of multi-megabyte embeds.)
On 29/05/2024 20:59, Michael S wrote:
On Wed, 29 May 2024 14:07:00 -0400Exactly. Windows costs a fortune.
James Kuyper <jameskuyper@alumni.caltech.edu> wrote:
On 29/05/2024 18:27, Malcolm McLean wrote:
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons,
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free. (And I buy these bare-bones. Machines with
Windows "pre-installed" are often cheaper because they are
sponsored by the junk-ware and ad-ware forced on unsuspecting
users.)
much less tolerant people then their counterparts at another
university, but that's another story). And I was given a brand new
Windows machine, and told that we had to use Linux. So I installed
a Linux version which ran on top of Windows. No good, I was told.
Might cause problems with that "interesting" set up. ...
They're quite right in that regard, as I can testify from personal
experience.
... So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
Keep in mind that, as David pointed out, the "waste" was probably
negative. You got a better price on the machine than you would have
otherwise, and erasing that malware gave you more space to put useful
stuff on your machine.
May be, for laptps that is true. But for mini-PCs it is very different.
Windows is surprisingly expensive in this case. OEM license is sold for
~75% of retail license price.
And Microsoft spend billions
developing it.
Baby X can't compete.
I never tested it myself, but I heard that there is a significant
difference in file access speed between WSL's own file system and
mounted Windows directories.
On 29/05/2024 22:46, Malcolm McLean wrote:
On 29/05/2024 20:59, Michael S wrote:
On Wed, 29 May 2024 14:07:00 -0400Exactly. Windows costs a fortune.
James Kuyper <jameskuyper@alumni.caltech.edu> wrote:
On 29/05/2024 18:27, Malcolm McLean wrote:
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons,
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free. (And I buy these bare-bones. Machines with
Windows "pre-installed" are often cheaper because they are
sponsored by the junk-ware and ad-ware forced on unsuspecting
users.)
much less tolerant people then their counterparts at another
university, but that's another story). And I was given a brand new
Windows machine, and told that we had to use Linux. So I installed
a Linux version which ran on top of Windows. No good, I was told.
Might cause problems with that "interesting" set up. ...
They're quite right in that regard, as I can testify from personal
experience.
... So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
Keep in mind that, as David pointed out, the "waste" was probably
negative. You got a better price on the machine than you would have
otherwise, and erasing that malware gave you more space to put useful
stuff on your machine.
May be, for laptps that is true. But for mini-PCs it is very different.
Windows is surprisingly expensive in this case. OEM license is sold for
~75% of retail license price.
Actually I've no idea how much it costs.
But whatever it is, I'm not adverse to the idea of having to pay for software. After all you have to pay for hardware, and for computers, I would happily pay extra to have something that works out of the box.
And Microsoft spend billions developing it.
Baby X can't compete.
Huh? I didn't know Baby X was an OS!
On Tue, 28 May 2024 23:08:22 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
My machine uses an SSD.
SSDs are not created equal. Especially for writes.
However the tests were run on Windows, so I ran your program again
under WSL; now it took 14 seconds (using both gcc-O3 and gcc-O2).
3 times slower ?!
I never tested it myself, but I heard that there is a significant
difference in file access speed between WSL's own file system and
mounted Windows directories. The difference under WSL is not as big
as under WSL2 where they say that access of mounted Windows filesystem
is very slow, but still significant.
I don't know if it applies to all file sizes or only to accessing many
small files.
On Wed, 29 May 2024 14:07:00 -0400
James Kuyper <jameskuyper@alumni.caltech.edu> wrote:
On 29/05/2024 18:27, Malcolm McLean wrote:
On 29/05/2024 13:10, David Brown wrote:
Yes, I got a job at Cambridge which didn't work out (Cantab dons,
It wasn't the cheapest available, and 64 GB memory (and 4 TB SSD)
don't come free. (And I buy these bare-bones. Machines with
Windows "pre-installed" are often cheaper because they are
sponsored by the junk-ware and ad-ware forced on unsuspecting
users.)
much less tolerant people then their counterparts at another
university, but that's another story). And I was given a brand new
Windows machine, and told that we had to use Linux. So I installed
a Linux version which ran on top of Windows. No good, I was told.
Might cause problems with that "interesting" set up. ...
They're quite right in that regard, as I can testify from personal
experience.
... So I had to scrub a brand new version of Windows.
It felt like the most extravagant waste.
Keep in mind that, as David pointed out, the "waste" was probably
negative. You got a better price on the machine than you would have
otherwise, and erasing that malware gave you more space to put useful
stuff on your machine.
May be, for laptps that is true. But for mini-PCs it is very different. Windows is surprisingly expensive in this case. OEM license is sold for
~75% of retail license price.
On 5/28/2024 6:24 PM, Michael S wrote:
On Tue, 28 May 2024 23:08:22 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
My machine uses an SSD.
SSDs are not created equal. Especially for writes.
However the tests were run on Windows, so I ran your program again
under WSL; now it took 14 seconds (using both gcc-O3 and gcc-O2).
3 times slower ?!
I never tested it myself, but I heard that there is a significant difference in file access speed between WSL's own file system and
mounted Windows directories. The difference under WSL is not as big
as under WSL2 where they say that access of mounted Windows
filesystem is very slow, but still significant.
I don't know if it applies to all file sizes or only to accessing
many small files.
WSL uses containers, <snip>
And no, companies like Intel or ASUS don't pay anything close to 75%
of the retail price for the Windows license they install.
On Thu, 30 May 2024 10:01:42 +0200
David Brown <david.brown@hesbynett.no> wrote:
And no, companies like Intel or ASUS don't pay anything close to 75%
of the retail price for the Windows license they install.
I don't know how much Intel or ASUS pays. I don't care about it.
What I do know and care about that for me, as a buyer, Intel or ASUS (I actually like Gigabyte Brix better, but recently they become too
expensive) mini-PC with Win11 Home will cost $140 more than exactly the
same box without Windows.
That's if bought it in big or medium store.
In little 1-2-men shop I can get legal Windows license on similar box
for, may be, $50. But I don't know if it will be a round 11 months
later if something breaks.
Pay attention that even in little shop mini-PC with Windows on it will
cost me more than the same box without OS. I didn't try it, but would
guess that [in a little shop] box with Linux preinstalled would cost me
~$25 above box without OS, i.e. still cheaper than with Windows.
On Tue, 28 May 2024 23:08:22 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
My machine uses an SSD.
SSDs are not created equal. Especially for writes.
However the tests were run on Windows, so I ran your program again
under WSL; now it took 14 seconds (using both gcc-O3 and gcc-O2).
3 times slower ?!
I never tested it myself, but I heard that there is a significant
difference in file access speed between WSL's own file system and
mounted Windows directories. The difference under WSL is not as big
as under WSL2 where they say that access of mounted Windows filesystem
is very slow, but still significant.
I don't know if it applies to all file sizes or only to accessing many
small files.
On 30/05/2024 09:33, Michael S wrote:
On Thu, 30 May 2024 10:01:42 +0200
David Brown <david.brown@hesbynett.no> wrote:
And no, companies like Intel or ASUS don't pay anything close to 75%
of the retail price for the Windows license they install.
I don't know how much Intel or ASUS pays. I don't care about it.
What I do know and care about that for me, as a buyer, Intel or ASUS (I
actually like Gigabyte Brix better, but recently they become too
expensive) mini-PC with Win11 Home will cost $140 more than exactly the
same box without Windows.
That's if bought it in big or medium store.
In little 1-2-men shop I can get legal Windows license on similar box
for, may be, $50. But I don't know if it will be a round 11 months
later if something breaks.
Pay attention that even in little shop mini-PC with Windows on it will
cost me more than the same box without OS. I didn't try it, but would
guess that [in a little shop] box with Linux preinstalled would cost me
~$25 above box without OS, i.e. still cheaper than with Windows.
40 years ago, my company made 8-bit business computers (my job was
designing the boards that went into them).
Adjusted for inflation, a floppy-based machine cost £4000, and one with
a 10MB HDD cost £9400.
They came with our own clone of CP/M, to avoid paying licence fees for it.
Compared to that, the cost of hardware now with a 4-6 magnitude higher
spec is peanuts, even with a premium for a pre-installed OS.
But suppose a high-spec machine now cost £1000; for someone using it
daily in their job, who might be paid a salary of £50-£100K or more, it
is again peanuts by comparison. Just their car to drive to work could
cost 20 times as much.
One tankful of fuel might cost the same as one Windows licence!
I'm astonished that professionals here are quibbling over the minor
extra margins needed to cover the cost of an important piece of software.
I guess the demand for a machine+Windows is high enough to get lower
volume pricing, while machine-only or machine+Linux is more niche?
On 30/05/2024 01:18, bart wrote:
On 29/05/2024 22:46, Malcolm McLean wrote:
Its an API. You call the Baby X API to get buttons and menus and other graphical elements, instead of Windows APIs. And it has just got its ownBaby X can't compete.
Huh? I didn't know Baby X was an OS!
file system.
On 29/05/2024 22:46, Malcolm McLean wrote:
Exactly. Windows costs a fortune.
Actually I've no idea how much it costs.
But whatever it is, I'm not adverse to the idea of having to pay for software. After all you have to pay for hardware, and for computers, I
would happily pay extra to have something that works out of the box.
And Microsoft spend billions developing it.
On 28/05/2024 16:34, David Brown wrote:
On 28/05/2024 13:41, Michael S wrote:
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
I used 100 MB of random data:
dd if=/dev/urandom bs=1M count=100 of=100MB
I compiled your code with "gcc-11 -O2 -march=native".
I ran everything in a tmpfs filesystem, completely in ram.
xxd took 5.4 seconds - that's the baseline.
Your simple C code took 4.35 seconds. Your second program took 0.9
seconds - a big improvement.
One line of Python code took 8 seconds :
print(", ".join([hex(b) for b in open("100MB", "rb").read()]))
That one took 90 seconds on my machine (CPython 3.11).
A slightly nicer Python program took 14.3 seconds :
import sys
bs = open(sys.argv[1], "rb").read()
xs = "".join([" 0x%02x," % b for b in bs])
ln = len(xs)
print("\n".join([xs[i : i + 72] for i in range(0, ln, 72)]))
This one was 104 seconds (128 seconds with PyPy).
This can't be blamed on the slowness of my storage devices, or moans
about Windows, because I know that amount of data (the output is 65%
bigger because of using hex format) could be processed in a couple of a seconds using a fast native code program.
It's just Python being Python.
(I have had reason to include a 0.5 MB file in a statically linked
single binary - I'm not sure when you'd need very fast handling of
multi-megabyte embeds.)
I have played with generating custom executable formats (they can be
portable between OSes, and I believe less visible to AV software), but
they require a normal small executable to launch them and fix them up.
To give the illusion of a conventional single executable, the program
needs to be part of that stub file.
There are a few ways of doing it, like simply concatenating the files,
but extracting is slightly awkward. Embedding as data is one way.
On 30/05/2024 02:18, bart wrote:
On 29/05/2024 22:46, Malcolm McLean wrote:
Exactly. Windows costs a fortune.
Actually I've no idea how much it costs.
The retail version is too much for a cheap machine, but a minor part
of the cost of a more serious computer. The server versions and
things like MSSQL server are ridiculous prices - for many setups,
they cost more than the hardware, and that's before you consider the
client access licenses.
But whatever it is, I'm not adverse to the idea of having to pay
for software. After all you have to pay for hardware, and for
computers, I would happily pay extra to have something that works
out of the box.
I have nothing against paying for software either. I mainly use
Linux because it is better, not because it is free - that's just an
added convenience. I have bought a number of Windows retail licenses
over the decades, to use with machines I put together myself rather
than OEM installations.
I'm not so sure about "works out of the box", however. On most
systems with so-called "pre-installed" Windows, it takes hours for
the installation to complete, and you need to answer questions or
click things along the way so you can't just leave it to itself. And
if the manufacturer has taken sponsorship from ad-ware and crap-ware
vendors, it takes more hours to install, and then you have hours of
work to uninstall the junk.
On Thu, 30 May 2024 13:31:18 +0200
David Brown <david.brown@hesbynett.no> wrote:
On 30/05/2024 02:18, bart wrote:
On 29/05/2024 22:46, Malcolm McLean wrote:
Exactly. Windows costs a fortune.
Actually I've no idea how much it costs.
The retail version is too much for a cheap machine, but a minor part
of the cost of a more serious computer. The server versions and
things like MSSQL server are ridiculous prices - for many setups,
they cost more than the hardware, and that's before you consider the
client access licenses.
It depends.
If you need Windows server just to run your own applications or
certain 3rd-party applications without being file server and without
being terminal server (i.e. at most 2 interactive users logged on simultaneously) then you can get away with Windows Server Essential.
It costs less than typical low end server hardware.
MS-SQL also has many editions with very different pricing.
I think, nowadays even Oracle has editions that is not ridiculously expensive. Not sure about IBM DB2.
But whatever it is, I'm not adverse to the idea of having to pay
for software. After all you have to pay for hardware, and for
computers, I would happily pay extra to have something that works
out of the box.
I have nothing against paying for software either. I mainly use
Linux because it is better, not because it is free - that's just an
added convenience. I have bought a number of Windows retail licenses
over the decades, to use with machines I put together myself rather
than OEM installations.
I'm not so sure about "works out of the box", however. On most
systems with so-called "pre-installed" Windows, it takes hours for
the installation to complete, and you need to answer questions or
click things along the way so you can't just leave it to itself. And
if the manufacturer has taken sponsorship from ad-ware and crap-ware
vendors, it takes more hours to install, and then you have hours of
work to uninstall the junk.
I don't remember anything like that in case of cheap mini-PC from my
previous post. It took a little longer than for previous mini-PC with
Win10 that it replaced, and longer than desktop with Win7, but we are
still talking about 10-15 minutes, not hours.
May be, quick Internet connection helps (but I heard that in Norway it
is quicker).
Or, may be, people that sold me a box, did some preliminary work.
Or, may be, your case of installation was very unusual.
On the other hand, I routinely see IT personal at work spending several
hours installing non-OEM Windows, esp. on laptops and servers. On
desktops it tends to be less bad.
On 30/05/2024 12:31, David Brown wrote:
On 30/05/2024 02:18, bart wrote:
IME installing Linux is faster and simpler than installing Windows on
almost any hardware. The only drivers that have been an issue for me
for decades is for very new Wireless interfaces.
So I wanted to add audio to Baby X.
And I stole an MP3 decoder from
Fabrice Bellard of tcc fame, and it took an afternoon to get audio up
and running under Baby X on Windows. Then do the samefor Linux. And it
was a complete nightmare, and it still isn't fit to push.
On Thu, 30 May 2024 00:40:07 -0400
Paul <nospam@needed.invalid> wrote:
On 5/28/2024 6:24 PM, Michael S wrote:
On Tue, 28 May 2024 23:08:22 +0100
bart <bc@freeuk.com> wrote:
On 28/05/2024 21:23, Michael S wrote:
On Tue, 28 May 2024 19:57:38 +0100
bart <bc@freeuk.com> wrote:
OK, I had go with your program. I used a random data file of
exactly 100M bytes.
Runtimes varied from 4.1 to 5 seconds depending on compiler. The
fastest time was with gcc -O3.
It sounds like your mass storage device is much slower than aging
SSD on my test machine and ALOT slower than SSD of David Brown.
My machine uses an SSD.
SSDs are not created equal. Especially for writes.
However the tests were run on Windows, so I ran your program again
under WSL; now it took 14 seconds (using both gcc-O3 and gcc-O2).
3 times slower ?!
I never tested it myself, but I heard that there is a significant
difference in file access speed between WSL's own file system and
mounted Windows directories. The difference under WSL is not as big
as under WSL2 where they say that access of mounted Windows
filesystem is very slow, but still significant.
I don't know if it applies to all file sizes or only to accessing
many small files.
WSL uses containers, <snip>
It seems, you are discussing a speed of access and methods of access
from the host side. My question is opposite - is access from Linux
guest to Windows host files running at the same speed as Linux (WSL,
not WSL2) guest to its own file system?
I heard that it isn't, but it was not conclusive and with insufficient details. I am going to test our specific case of big files. Now.
On 29/05/2024 23:08, bart wrote:while the Linux system was installed about 6 years ago. Both machines have a number of other programs open (the Linux machine has vastly more), but none of these are particularly demanding when not in direct use.
On 28/05/2024 16:34, David Brown wrote:
On 28/05/2024 13:41, Michael S wrote:
Let's start another round of private parts' measurements turnament!
'xxd -i' vs DIY
I used 100 MB of random data:
dd if=/dev/urandom bs=1M count=100 of=100MB
I compiled your code with "gcc-11 -O2 -march=native".
I ran everything in a tmpfs filesystem, completely in ram.
xxd took 5.4 seconds - that's the baseline.
Your simple C code took 4.35 seconds. Your second program took 0.9 seconds - a big improvement.
One line of Python code took 8 seconds :
print(", ".join([hex(b) for b in open("100MB", "rb").read()]))
That one took 90 seconds on my machine (CPython 3.11).
A slightly nicer Python program took 14.3 seconds :
import sys
bs = open(sys.argv[1], "rb").read()
xs = "".join([" 0x%02x," % b for b in bs])
ln = len(xs)
print("\n".join([xs[i : i + 72] for i in range(0, ln, 72)]))
This one was 104 seconds (128 seconds with PyPy).
This can't be blamed on the slowness of my storage devices, or moans about Windows, because I know that amount of data (the output is 65% bigger because of using hex format) could be processed in a couple of a seconds using a fast native code program.
It's just Python being Python.
I have two systems at work with close to identical hardware, both about 10 years old. The Windows one has a little bit faster disk, the Linux one has more memory, but the processor is the same. The Windows system is Win7 and as old as the machine,
On the Linux machine, that program took 25 seconds (with python 3.7). On the Windows machine, it took 48 seconds (with python 3.8). In both cases, the source binary file was recently written and therefore should be in cache, and both the source anddestination were on the disk (ssd for Windows, hd for Linux).
Python throws all this kind of stuff over to the C code - it is pretty good at optimising such list comprehensions. (But they are obviously still slower than carefully written native C code.) If it were running through these loops with theinterpreter, it would be orders of magnitude slower.
So what I see from this is that my new Linux PC took 14 seconds while my old Linux PC took 25 seconds - it makes sense that the new processor is something like to 80% faster than the old one for a single-threaded calculation. And Windows (noting thatthis is Windows 7, not a recent version of Windows) doubles that time for some reason.
and have that pass on updates to the other devices. So the firmware for the other devices will be built into the executable for the master board.
(I have had reason to include a 0.5 MB file in a statically linked single binary - I'm not sure when you'd need very fast handling of multi-megabyte embeds.)
I have played with generating custom executable formats (they can be portable between OSes, and I believe less visible to AV software), but they require a normal small executable to launch them and fix them up.
To give the illusion of a conventional single executable, the program needs to be part of that stub file.
There are a few ways of doing it, like simply concatenating the files, but extracting is slightly awkward. Embedding as data is one way.
Sure.
The typical use I have is for embedded systems where there is a network with a master card and a collection of slave devices (or perhaps multiple microcontrollers on the same board). A software update will typically involve updating the master board
Another use-case is small web servers in program, often for installation, monitoring or fault-finding. There are fixed files such as index.html, perhaps a logo, and maybe jquery or other javascript library file.
On 5/30/2024 3:40 AM, Michael S wrote:
On Thu, 30 May 2024 00:40:07 -0400
Notice I dropped my caches (which on modern Linux is mostly a waste
of time, as there still seem to be caches in there -- benching and >eliminating caches is tough to do now).
WSL Ubuntu20.04 version 2
On 5/30/2024 9:05 AM, David Brown wrote:
On 29/05/2024 23:08, bart wrote:
On 28/05/2024 16:34, David Brown wrote:So what I see from this is that my new Linux PC took 14 seconds
On 28/05/2024 13:41, Michael S wrote:
while my old Linux PC took 25 seconds - it makes sense that the new
processor is something like to 80% faster than the old one for a
single-threaded calculation. And Windows (noting that this is
Windows 7, not a recent version of Windows) doubles that time for
some reason.
Did you turn off Windows Defender while benching ?
[Picture]
https://i.postimg.cc/QCgLJLHQ/windows11-AV-off-control.gif
Benching on Windows is an art, because of all the crap going
on under the hood.
I've had programs slowed to 1/8th normal speed to 1/20th normal
speed, by forgetting to turn off a series of things. Once all
that is done, now you're getting into the same ballpark as Linux.
I also have to turn off the crap salad in Windows, when Windows Update
is running!!!
The OS is too stupid to optimize conditions for its
own activity. My laptop for example, ran out of RAM, because "SearchApp"
was eating a three-course meal while I was working. Attempting to kill
that mother, caused the incoming Update to install at closer to normal
speed.
It takes practice to get good at benching modern Windows. On
an OS like Windows 2000, it was always ready to bench. It came
with no AV. It had no secret agenda. It just worked. Each succeeding
version is more of a nightmare.
Imagine when the local AI is running on the machine, and the power consumption is 200W while it "listens to your voice". At least they're staying true to their design principles.
Imagine turning off (or never enabling) the services that you don't
find useful and can be a significant drain. I always disable Windows updates, indexing services, and would never have a "voice AI" on a
computer. Linux does not have anything like as much of this kind of
nonsense on normal desktops (though I believe Ubuntu had some nasty
automatic search systems for a while). The only one I can think of
is "updatedb" for the "locate" command. While "locate" can sometimes
be useful, trawling the filesystem can be very time-consuming if it
is large. But it's easy to tune updatedb to cover only the bits you
need.
On Fri, 31 May 2024 09:55:49 +0200
David Brown <david.brown@hesbynett.no> wrote:
Imagine turning off (or never enabling) the services that you don't
find useful and can be a significant drain. I always disable Windows
updates, indexing services, and would never have a "voice AI" on a
computer. Linux does not have anything like as much of this kind of
nonsense on normal desktops (though I believe Ubuntu had some nasty
automatic search systems for a while). The only one I can think of
is "updatedb" for the "locate" command. While "locate" can sometimes
be useful, trawling the filesystem can be very time-consuming if it
is large. But it's easy to tune updatedb to cover only the bits you
need.
Most of the things that you mentioned above are not easy to achieve on
Home Editions of Windows beyond 7.
Some of them are not easy to achieve even on Pro edition.
That's a major reason for me to remain on 7 for as long as I can.
On Thu, 30 May 2024 14:04:39 -0400
Paul <nospam@needed.invalid> wrote:
WSL Ubuntu20.04 version 2
Are you sure that you tested WSL, not WLS-2?
Your results looks very much like WLS2.
Your explanationns sound very much as if you are talking about WSL-2.
My WSL testing results are opposit from yours - read speed identical,
write speed consitently faster when writing to /mnt/d/... then when
writing to WSL's native FS.
Part of the reason could be that SSD D: is physically faster than SSD
C: that hosts WSL. I should have tested with /mnt/c as well, but
forgot to do it.
Did you turn off Windows Defender while benching ?
The only one I can think of is
"updatedb" for the "locate" command. While "locate" can sometimes be
useful, trawling the filesystem can be very time-consuming if it is
large. But it's easy to tune updatedb to cover only the bits you need.
On Fri, 31 May 2024 09:55:49 +0200, David Brown wrote:
The only one I can think of is
"updatedb" for the "locate" command. While "locate" can sometimes be
useful, trawling the filesystem can be very time-consuming if it is
large. But it's easy to tune updatedb to cover only the bits you need.
On Linux, there is the concept of “ionice”, which is to I/O what “nice” is
to CPU usage. So for example if updatedb had its ionice dropped to “idle” priority, that allows it to be pushed to the back of the queue when
regular apps need to do any I/O. Result is much less system impact from
such background update tasks.
Maybe there’s an option to set this somewhere?
In fact, I think /all/ the pre-built ones have Windows.
Windows costs a fortune. And Microsoft spend billions
developing it.
WSL uses containers, so of course it is slow.
On Thu, 30 May 2024 00:40:07 -0400, Paul wrote:
WSL uses containers, so of course it is slow.
WSL1 had a Linux “personality” on top of the NT kernel. So this was emulation, not containers.
WSL2 uses Hyper-V to run Linux inside a VM. Again, not containers.
Linux has containers, which are based entirely on namespace isolation (and cgroups for process management). These are all standard kernel mechanisms,
so there should be very little overhead in using them.
Am 29.05.2024 um 14:10 schrieb David Brown:
I've seen odd things with timings due to Windows' relatively poor IO,
file and disk handling. Many years ago when I had need of
speed-testing some large windows-based build system, I found it was
faster running in a virtual windows machine on VirtualBox on a Linux
host, than in native Windows on the same hardware.
Windows kernel I/O is rather efficient ...
Conclusion: beating xxd is apparently not hard if even a scripting
language can do so. I wonder what slows it down?
Standard PC's and laptops are very low-margin products.
If WSL were to work by containers, it would need to run the Linux
processes as processes under the NT kernel. I suppose that might be possible, with a translation layer for all system API calls. After all,
you can run Windows processes on Linux with Wine - perhaps a similar principle can work for Windows?
On Thu, 30 May 2024 00:40:07 -0400, Paul wrote:
WSL uses containers, so of course it is slow.
WSL1 had a Linux “personality” on top of the NT kernel. So this was emulation, not containers.
WSL2 uses Hyper-V to run Linux inside a VM. Again, not containers.
Linux has containers, which are based entirely on namespace isolation
(and cgroups for process management). These are all standard kernel mechanisms, so there should be very little overhead in using them.
On Thu, 30 May 2024 10:01:42 +0200, David Brown wrote:
In fact, I think /all/ the pre-built ones have Windows.
I have set up two MSI Cubi 5 machines for friends, both with Linux
Mint. Neither came with Windows, either in the box or preinstalled.
For new systems that don't have the
legacy requirements, customers will wonder why they should buy one of
these when something like PostgreSQL is free, has most of the features (including its own unique ones), and will happily scale to the huge
majority of database needs.
Hardly anybody uses the WinAPI directly.
On Wed, 29 May 2024 21:31:54 +0100, bart wrote:
Conclusion: beating xxd is apparently not hard if even a scripting
language can do so. I wonder what slows it down?
It’s written in a very stdio-dependent vanilla C style.
Have a look at the source for yourself. It’s part of the “vim”
package on Debian and no doubt other distros. The xxd binary itself
is built from a single source file of just some 1200 lines, and the hex-to-binary conversion is done in a function called “huntype” of
just 133 lines.
On Mon, 3 Jun 2024 03:15:27 -0000 (UTC)
Lawrence D'Oliveiro <ldo@nz.invalid> wrote:
On Thu, 30 May 2024 00:40:07 -0400, Paul wrote:
WSL uses containers, so of course it is slow.
WSL1 had a Linux “personality” on top of the NT kernel. So this was
emulation, not containers.
WSL2 uses Hyper-V to run Linux inside a VM. Again, not containers.
Linux has containers, which are based entirely on namespace isolation
(and cgroups for process management). These are all standard kernel
mechanisms, so there should be very little overhead in using them.
The word "container" has many meanings.
As far as host FS is concerned, guest FS is a one huge file. Despite
very different tech under the hood it equally applies both to WSL and
to WSL-2. Calling this file 'container' sounds like proper use of the
term.
MSVC quitted compilation after allocating 50GB of
memory, gcc and clang compiled for minutes.
On Mon, 3 Jun 2024 03:15:27 -0000 (UTC)
Lawrence D'Oliveiro <ldo@nz.invalid> wrote:
Linux has containers, which are based entirely on namespace isolation
(and cgroups for process management). These are all standard kernel
mechanisms, so there should be very little overhead in using them.
The word "container" has many meanings.
As far as host FS is concerned, guest FS is a one huge file.
There's a good reason for sth. like #embed: I just wrote a very quick
xxd alternative and generated a C-file with a char-array and the size
of this file is 1,2GB. MSVC quitted compilation after allocating 50GB
of memory, gcc and clang compiled for minutes. This would be better
with an #embed-Tag. So there's really good reason for that.
This is my xxd-substitude. Compared to xxd it only can dump C-files.
On my PC it's about 15 times faster than xxd because it does its own I/O-buffering.
#include <iostream>
#include <fstream>
#include <charconv>
#include <span>
#include <vector>
using namespace std;
int main( int argc, char **argv )
{
if( argc < 4 )
return EXIT_FAILURE;
char const
*inFile = argv[1],
*symbol = argv[2],
*outFile = argv[3];
ifstream ifs;
ifs.exceptions( ifstream::failbit | ifstream::badbit ); ifs.open( inFile, ifstream::binary | ifstream::ate ); streampos size( ifs.tellg() );
if( size > (size_t)-1 )
return EXIT_FAILURE;
ifs.seekg( ifstream::beg );
union ndi { char c; ndi() {} };
vector<ndi> rawBytes( size );
span<char> bytes( &rawBytes.data()->c, rawBytes.size() ); ifs.read( bytes.data(), bytes.size() );
ofstream ofs;
ofs.exceptions( ofstream::failbit | ofstream::badbit ); ofs.open( outFile );
vector<ndi> rawBuf( 0x100000 );
span<char> buf( &rawBuf.begin()->c, rawBuf.size() );
ofs << "unsigned char " << symbol << "[" << (size_t)size << "] = \n{\n";
auto rd = bytes.begin();
auto wrt = buf.begin();
auto flush = [&]
{
ofs.write( buf.data(), wrt - buf.begin() );
wrt = buf.begin();
};
while( rd != bytes.end() )
{
size_t remaining = bytes.end() - rd;
constexpr size_t N_LINE = 1 + 12 * 6 - 1 + 1;
size_t n = remaining > 12 ? 12 : remaining;
auto rowEnd = rd + n;
*wrt++ = '\t';
do
{
*wrt++ = '0';
*wrt++ = 'x';
char *wb = to_address( wrt );
(void)(wrt + 2);
auto tcr = to_chars( wb, wb + 2, (unsigned char)*rd++, 16 );
if( tcr.ptr == wb + 1 )
wb[1] = wb[0],
wb[0] = '0';
wrt += 2;
if( rd != bytes.end() )
{
*wrt++ = ',';
if( rd != rowEnd ) *wrt++ = ' ';
}
} while( rd != rowEnd );
*wrt++ = '\n';
if( buf.end() - wrt < N_LINE )
flush();
}
flush();
ofs << "};\n" << endl;
}
Am 04.06.2024 um 04:07 schrieb Lawrence D'Oliveiro:
On Mon, 3 Jun 2024 18:39:55 +0200, Bonita Montero wrote:
MSVC quitted compilation after allocating 50GB of
memory, gcc and clang compiled for minutes.
Next time, don’t even bother with MSVC.
MSVC has the most conforming C++20-frontend.
On Tue, 4 Jun 2024 04:46:59 +0200, Bonita Montero wrote:
Am 04.06.2024 um 04:07 schrieb Lawrence D'Oliveiro:
On Mon, 3 Jun 2024 18:39:55 +0200, Bonita Montero wrote:
MSVC quitted compilation after allocating 50GB of
memory, gcc and clang compiled for minutes.
Next time, don’t even bother with MSVC.
MSVC has the most conforming C++20-frontend.
Somehow I find that hard to believe <https://gcc.gnu.org/gcc-14/changes.html#cxx>.
On Mon, 3 Jun 2024 18:39:55 +0200, Bonita Montero wrote:
MSVC quitted compilation after allocating 50GB of
memory, gcc and clang compiled for minutes.
Next time, don’t even bother with MSVC.
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 546 |
| Nodes: | 16 (2 / 14) |
| Uptime: | 149:05:05 |
| Calls: | 10,383 |
| Calls today: | 8 |
| Files: | 14,054 |
| D/L today: |
2 files (1,861K bytes) |
| Messages: | 6,417,763 |
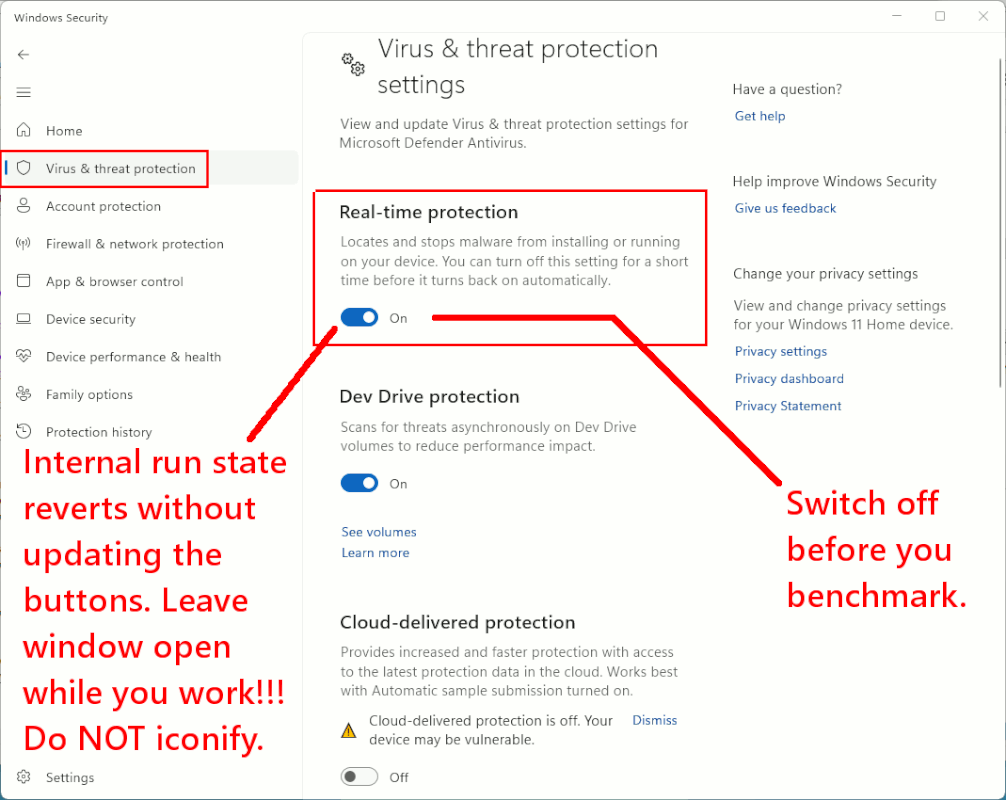{kind=link}
{kind=link}