now 1649120014 s
ok
exec time: 53.366160 s
now 1649120014 s
dif 0 s
Presione una tecla para continuar . . .
now 1649120014 s
ok
exec time: 53.366160 s
now 1649120014 s
dif 0 s
Presione una tecla para continuar . . .
you can ignore this, is just another test with extra checking, you can see exec time is 53 s about the same of the linux shell measure with time p.pl
$ time ./p.pl
ok
real 0m 52.30s
user 0m 52.12s
sys 0m 0.01s
with p.l :
#!/bin/perl
$s = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa";
if ( $s =~ /a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa/ ){
print "ok\n";
}
thank you. Yes, TCL is sometimes quite fast.
AFAIK, the used regexp lib requires UTF-16 data input.
In consequence, each string must be converted from utf-8 to utf-16
first. As TCL has no utf-16 internal string type, the conversion is done quite frequently. Also other utf-16 interfaces like the Windows OS API require this constant conversion. There is the idea to also support
utf-16 as internal data type form many commands, so we do not need to
recode so often. I suppose, this would again boost the regexp performance.
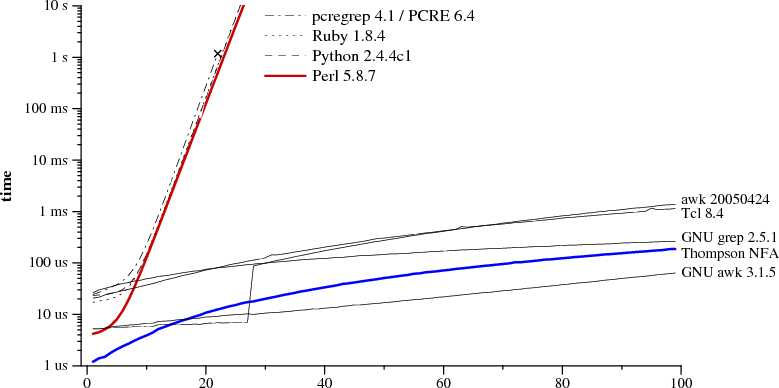
I was reading an article [1] about algorithms implementing regular expressions when I saw this picture [2], tcl regex performance is six orders of magnitude faster than perl regex for certain regular expression, I was really shocked and couldn'tbelieve it
Furthermore, the engine is not any longer maintained IIRC. I cannot off
the top of my head find the citations for this, but overall, I'm not
overly convinced, unfortunately.
On 4/5/2022 2:47 AM, pd wrote:
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]"
a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
A lot goes on behind the scenes in tcl. There's caching of the r.e. expression going on somewhere.
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]" a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
Am 06.04.22 um 21:25 schrieb jtyler:
On 4/5/2022 2:47 AM, pd wrote:
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]"
a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
A lot goes on behind the scenes in tcl. There's caching of the r.e.
expression going on somewhere.
That's not the reason: the regexp engine in Tcl transform the NFA for
the regexp into a DFA - those are two standard implementations for
regexp state machines. For some specially crafted REs like the ones
above, with many overlapping matches, the NFA becomes very slow -
exponential runtime in the length of the expression, IIRC - whereas the
DFA still works quickly.
You cand find an overview comparison of these algorithms here:
https://zherczeg.github.io/sljit/regex_compare.html
Christian
On 4/6/2022 1:00 PM, Christian Gollwitzer wrote:
Am 06.04.22 um 21:25 schrieb jtyler:
On 4/5/2022 2:47 AM, pd wrote:
% set s [string repeat a 30]
aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% set r "[string repeat a? 30][string repeat a 30]"
a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa
% time {regex $r $s m}
199 microseconds per iteration
A lot goes on behind the scenes in tcl. There's caching of the r.e.
expression going on somewhere.
That's not the reason: the regexp engine in Tcl transform the NFA for
the regexp into a DFA - those are two standard implementations for
regexp state machines. For some specially crafted REs like the ones
above, with many overlapping matches, the NFA becomes very slow -
exponential runtime in the length of the expression, IIRC - whereas
the DFA still works quickly.
You cand find an overview comparison of these algorithms here:
https://zherczeg.github.io/sljit/regex_compare.html
Christian
Isn't there some caching going on as well?
Or can you think of some other reason why the second run is so much
faster than the first?
I seem to recall reading somewhere that the tcl_obj has a type of r.e.
that it can reuse in the same way as shimmering between strings and
binary numbers. Could that be the case here?
You can check this for yourself easily with
tcl::unsupported::representation:
(chris) 50 % set RE {a*b}
a*b
(chris) 51 % ::tcl::unsupported::representation $RE
value is a pure string with a refcount of 5, object pointer at 0x7f823f35a7f0, string representation "a*b"
(chris) 52 % regexp $RE "blaaaaaab"
1
(chris) 53 % ::tcl::unsupported::representation $RE
value is a regexp with a refcount of 4, object pointer at
0x7f823f35a7f0, internal representation 0x7f823f36b910:0x7f823f35b150,
string representation "a*b"
Christian
On 4/6/2022 10:26 PM, Christian Gollwitzer wrote:
Thanks, I was confusing tcl objects, I thought the object was the
variable, not the data.
Below I see that it doesn't increment the ref counter for the $RE, but
does when a*b is entered literally, but they are the same object.
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 496 |
| Nodes: | 16 (3 / 13) |
| Uptime: | 65:03:52 |
| Calls: | 9,764 |
| Calls today: | 5 |
| Files: | 13,745 |
| Messages: | 6,185,832 |
{kind=link}