For adduser's next release, I would like to discuss the following
things:
(1)
Should Debian allow UTF-8 user names in the first place or should we
restrict names for regular users to some us-ascii near set as well? (I
think yes, we should)
P.S.: The teams and inviduals working on src:shadow, base-passwd and
adduser would appreciate your help in coding and packaging.
[writing this with my adduser hat on. I am also in touch with the
maintainers of src:shadow and base-passwd]
Hi,
recently, I have "taken over" the wiki page about UserAccounts and have
put in some history and general thoughts about what Debian thinks about
user names and name restrictions.
https://wiki.debian.org/UserAccounts
I fear that I have opened an especially nasty can of worms by beginning
to do sanity checks in adduser and being pointed towards user name
encoding in that process. Can you help me to bring some sense into this
mess?
I would like to hear your comments. Feel free to directly apply
corrections to the wiki page. I am especially interested in having clear terminology regarding unicode codepoints, UTF-8, character strings and
byte strings. It is vitally important to be consistent her to avoid
making the mess even worse.
For adduser's next release, I would like to discuss the following
things:
(1)
Should Debian allow UTF-8 user names in the first place or should we
restrict names for regular users to some us-ascii near set as well? (I
think yes, we should)
On 2024-11-21 18:45:06, Marc Haber wrote:
Should Debian allow UTF-8 user names in the first place or should we restrict names for regular users to some us-ascii near set as well? (I think yes, we should)
You weren't clear to which part you agreed. If by "we should" you meant
the closest option, i.e. restrict, then I agree as well.
As Richard also replied, full UTF-8 is tricky,
and I think it's somewhat
misplaced to focus on the username, as opposed to gecos. Aren't most
other OSes using the "full name" as the "display name", and the username
is mostly one part of the user/password combination, but not a display property most of the time?
So I would suggest that maybe the better option is to standardise the
gecos format/gecos parsing, so migrate UI tools to use that more often.
On the other hand, as long as this is admin-controlled, it doesn't
matter much. I could see that viewpoint, but I wonder how much latent breakage would be introduced that will take years to fix in all tooling
and all packages.
Marc Haber <mh+debian-devel@zugschlus.de> writes:
For adduser's next release, I would like to discuss the following
things:
(1)
Should Debian allow UTF-8 user names in the first place or should we restrict names for regular users to some us-ascii near set as well? (I think yes, we should)
would allowing utf-8 enable some of the abuse described at https://lwn.net/Articles/874951/ ?
as usernames appear in logs and other output (and are passed to all
sorts of commands), it seems a bad idea to be too permissive or to
change from historic practice by default, even though from a user pov it would be nice to have the option
P.S.: The teams and inviduals working on src:shadow, base-passwd and adduser would appreciate your help in coding and packaging.
Is there a list of "things that need doing"?
would allowing utf-8 enable some of the abuse described at >https://lwn.net/Articles/874951/ ?I have no experience with bidirectional attacks, but browsers
as usernames appear in logs and other output (and are passed to all
sorts of commands), it seems a bad idea to be too permissive or to
change from historic practice by default, even though from a user pov it >would be nice to have the option
I have no experience with bidirectional attacks, but browsers mitigate homograph attacks in IDNs by disallowing mixed alphabets such as cyrillic
and latin letters in the same name. That seems to be a reasonable
restriction for user names as well.
I might be naive here , but I don't have much experience with non-ascii
names since I have the privilege of being fluent in two languages that
use the latin alphabet.
On the other side, wouldnt it be a courtesy to allow people having a
name that needs transcription to be written in latin to use their name
in the real alphabet that it is usually written in as a login name as
well? To make things worse, transcriptions are often ambigious.
I would like to hear the opinion of people who would be affected by this change.
I tried to consider what it would take to have an émollier or an
Émollier login, and there is one little blocker : I may have to
login from environments or keyboards lacking the necessary i18n
and l10n capabilities to transcribe the 'e' acute, let alone the
uppercase 'e' acute.
On 22/11/24 20:42, Étienne Mollier wrote:
I tried to consider what it would take to have an émollier or an
Émollier login, and there is one little blocker : I may have to
login from environments or keyboards lacking the necessary i18n
and l10n capabilities to transcribe the 'e' acute, let alone the
uppercase 'e' acute.
Dear Étienne,
your case highlights another problem not mentioned in the original list posted by Marc: comparison (and normalization).
Some characters can be encoded in more than one way. For instance, "é" in "émollier" could we stored as "e with acute" U+00E9 (and encoded in UTF-8 as 0xc3 0xa9) or as "e, combined with an acute accent" U+0065 plus U+0301 (UTF-8: 0x65 0xcc 0x81). If a keyboard input system provides the former sequence of bytes, but the username is stored in the login infrastructure using the latter sequence of bites, then a naive comparison will not find
the user "émollier" in the system. Unicode defines in Annex 15 a few normalization forms as a way to work around this problem. But a correct use of these normalization forms still requires coordination and standardization among all programs accessing the data.
Does POSIX (or other de-facto standards) prescribe a normalization form for Unicode-/UTF-8-encoded usernames?
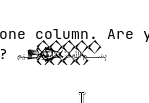
You now have glyphs which occupy more than one column. Are your columnar/tabular programs prepared for that? ﷽𒁭𒐫i
But my 2 cents on the topic are: Lets please allow more than ascii in usernames.
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
On the other hand, as long as this is admin-controlled, it doesn't
matter much. I could see that viewpoint, but I wonder how much latent
breakage would be introduced that will take years to fix in all tooling
and all packages.
Yes. Fixing breakage makes software better, and by disallowing non-latin characters in user names we are hiding those issues away.
Gioele Barabucci left as an exercise for the reader:
On 23/11/24 09:32, Johannes Schauer Marin Rodrigues wrote:
But my 2 cents on the topic are: Lets please allow more than ascii in
usernames.
potentially insecure (homographs) and at
high-risk of breaking existing applications (lack of standardized
normalization form).
i'm not sure why this is being repeated.
https://unicode.org/reports/tr15/
Johannes Schauer Marin Rodrigues <josch@mister-muffin.de> writes:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students
that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
You are confusing usernames and names. Different concepts with
different rules. Let's just hope you never get two students with the
same name.
Johannes Schauer Marin Rodrigues <josch@mister-muffin.de> writes:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students
that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
You are confusing usernames and names. Different concepts with
different rules. Let's just hope you never get two students with the
same name.
* Bjørn Mork <bjorn@mork.no> [241124 11:45]:
Johannes Schauer Marin Rodrigues <josch@mister-muffin.de> writes:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students
that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
You are confusing usernames and names. Different concepts with
different rules. Let's just hope you never get two students with the
same name.
I find your reply massively insulting, and I'm not even the original
author.
Usernames (not the "comment" field) are identifiers, and humans care
about the identifiers used for them.
Yes, some humans don't care if you assign them a random 32byte
string as their username. Enough humans however, do have
preferences. In some countries humans even have a right to choose
how they are being adressed.
As Richard also replied, full UTF-8 is tricky, and I think it's somewhat misplaced to focus on the username, as opposed to gecos. Aren't most
other OSes using the "full name" as the "display name", and the username
is mostly one part of the user/password combination, but not a display property most of the time?
So I would suggest that maybe the better option is to standardise the
gecos format/gecos parsing, so migrate UI tools to use that more often.
On 2024-11-24 14:37:24, Chris Hofstaedtler wrote:
* Bjørn Mork <bjorn@mork.no> [241124 11:45]:
Johannes Schauer Marin Rodrigues <josch@mister-muffin.de> writes:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students
that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
You are confusing usernames and names. Different concepts with
different rules. Let's just hope you never get two students with the same name.
I find your reply massively insulting, and I'm not even the original author.
Massively?
Usernames (not the "comment" field) are identifiers, and humans care
about the identifiers used for them.
Yes, some humans don't care if you assign them a random 32byte
string as their username. Enough humans however, do have
preferences. In some countries humans even have a right to choose
how they are being adressed.
And what relation does the username used for logging in have to "being addressed"? Isn't it akin a passport/ID card number?
[...]
I still don't understand the need for username to be very
representative of one's name. OTOH, my name can be fully written
using
ASCII, so maybe I miss something. But I've also had to use accounts
like
abc745, which didn't bother me much over the duration of a semester
or
year.
Quoting nick black (2024-11-23 08:48:10)
You now have glyphs which occupy more than one column. Are your columnar/tabular programs prepared for that? ﷽𒁭𒐫i
xfce-terminal renders this like this: https://mister-muffin.de/p/4o2v.png
No idea if this is correct and I'll leave the details to those who know more about this topic than I. And maybe my email client completely messes this up in
this response of mine.
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
If having this work in Debian can put a bit on pressure on those software projects that do not support this, then please let that happen so that missing
unicode support becomes more annoying for those pieces of software that are missing it. For example, if my email client messed this up, then lets fix it. We cannot find these kind of bugs if we accept translating everybody's given name to the American alphabet.
Thanks!
cheers, josch
No. I see and type my username hundreds times a day, people use it
to address me in written and spoken conversations with it, etc.
Moreover, adduser man page on Debian stable, states
that gecos fields will be removed after bookworm.
Chris Hofstaedtler <zeha@debian.org> writes:
No. I see and type my username hundreds times a day, people use it
to address me in written and spoken conversations with it, etc.
This is confusing the subject even more.
Are you sure you are talking about usernames? Or is this email local
parts, chat nicknames and spoken nicks? If so, then there is no reason
you can't use utf8. Today. Without changing any username.
Marc Haber <mh+debian-devel@zugschlus.de> writes:
On the other hand, as long as this is admin-controlled, it doesn't
matter much. I could see that viewpoint, but I wonder how much latent
breakage would be introduced that will take years to fix in all tooling
and all packages.
Yes. Fixing breakage makes software better, and by disallowing non-latin characters in user names we are hiding those issues away.
This is arrogant.
Assuming that a username can be displayed, sorted,
compared and typed using strict us-ascii is not a bug today. It's not "hiding" any issue.
The question is whether it makes sense to introduce a new class of bugs
by changing the rules. And we can pretty much guarantee that some of
those bugs are securty critical, since this is all about authentication
and authorization.
For what purpose?
But my 2 cents on the topic are: Lets please allow more than ascii in usernames. I find it very uncomfortable every time I have to tell my students that sorry, you somehow have to manage writing your name using American letters
because that's all we have after half a century of Computers being a thing...
On 23/11/24 09:32, Johannes Schauer Marin Rodrigues wrote:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames.
Yes please, but opt-in and behind a big red warning that says that it is not interoperable (outside POSIX),
potentially insecure (homographs) and at
high-risk of breaking existing applications (lack of standardized normalization form).
PS: My personal, ignorant, Latin-world opinion is that it is probably
too hard for most people to type each others' usernames if UTF-8 were to
be allowed.
Marc Haber left as an exercise for the reader:
(1)
Should Debian allow UTF-8 user names in the first place or should we restrict names for regular users to some us-ascii near set as well? (I think yes, we should)
I feel strongly yes, despite POSIX admonitions (quoted elsewhere
in this thread) and sure breakage any number of places.
I think
a test plan would be very desirable (off the top of my head,
we'd want to check login, the DMs, PAM, OpenSSH, passwd, w,
framebuffer console input, etc. It would probably also be a good
idea to loop in other distributions.
I recommend Chapter 7 of my free book, "Hacking the Planet with
Notcurses: A Guide to TUIs and Character Semigraphics" for the
full story (as I understand it) regarding Unicode presentation: https://nick-black.com/htp-notcurses.pdf (starts on page 41).
* any upstream tool could say "bad idea" and refuse patches,
requiring their long term management,
* the Linux framebuffer console is pretty limited in what
glyphs it has available, and the number of glyphs it can
support,
* you want installer support if you intend to do this right,
* ubiquitous input for UTF-8 is a pretty complicated story, and
* broken localization (or failure to call setlocale()) could be
a bigger problem, especially for root/system accounts.
Other concerns:
You'll likely now be linking libunistring into some
binaries where it wasn't previously used.
Regarding the subset of Unicode characters you'd want to allow,
this would be best decided using the General Category trait.
Each codepoint is assigned one of a finite set of General
Categories. We would probably want to allow Letters, Marks, and
Numbers, and perhaps a whitelist from Punctuation and Symbols
(Punctuation, connector and Punctuation, dash are probably all
we'd want) extended from currently supported ispunct(3)
characters. This data is available from libunistring (and
probably other places). This eliminates a great swatch of known
security issues.
Names containing invalid UTF-8 sequences ought be rejected.
Characters 0-127 would presumably be allowed iff they are now;
UTF-8 preserves US-ASCII.
We ought support combining characters up through the Extended
Grapheme Cluster (a single user-perceived character, roughly a
glyph, made up of one or more encoded characters). Generally a
single backspace ought map to an entire EGC.
Regarding canonicalization/normalization, this is a complex
question without a necessarily correct technical answer. I think
you'd want to follow the Principle of Least Astonishment; as to what
would astonish the least, I'd like to hear wider input. But
Unicode definitely defines multiple normal forms and equivalency
classes.
You now have glyphs which occupy more than one column. Are your columnar/tabular programs prepared for that? ﷽𒁭𒐫
(2)
If the answer to (1) is "allow UTF-8", should we also do that for system users? (I think no, we should not)
I think you should, simply because otherwise you have two paths
in more places.
(3)
I think that 32 characters/bytes (it's the same if we don't allow UTF-8)
is a good limitation for a system user name. But, should we increase
that for regular user names? (I think yes)
I hesitate to comment here because who really cares, but does 32
save us something over 128? 128 seems the default "enough for
everybody" these days, looking at IPv6 and ZFS.
My printer is administered by i̸̒n̴͛e̵̎l̴͝u̷̾c̴̉t̵́å̵b̷͋l̷͐e̴̋m̸̆o̷̚d̴̐ä̸́l̶͝i̷̋t̷͗ẏ̷ȏ̵f̸̃t̶͘h̷͗e̴̿v̶͘i̷̛s̸̈́ì̵b̷̃l̶̎e̷͊.
(6)
Does it still make sense to give non-UTF-8-locales special handling
(which one?), or can adduser safely assume that any non-ascii locale is UTF-8? Or must I check for locale and reject UTF-8 user names on
non-UTF-8 locales? (I hope that we can safely assume UTF-8)
It cannot. "C" is not UTF-8. Assumption of UTF-8 requires a
properly set LANG and programs calling setlocale(). This, as
alluded to above, has the potential for a big mess.
I think one good idea that we should certainly adopt from <https://systemd.io/USER_NAMES/> is its separation between "strict mode"
(the naming convention that it encourages for all uses, and enforces
when a user is created via systemd tools) and "relaxed mode" (the much
less strict naming convention that systemd requires for names created by non-systemd tools). Because of the differences between those two modes, systemd is quite conservative in what its own tools will emit but a
lot more liberal in what it will accept, and that seems like a good
principle here, even if the specific rules that Debian chooses end up differing from those that systemd has chosen.
It is true that user account name and user (display) name are
different, of course. But still, when you log in, you use the user
account name to the access system; this is the text shown in file
ownership listing and almost everywhere in the system.
I think that user (display) name, that may be put in gecos field, are
not widely used.
Moreover, adduser man page on Debian stable, states
that gecos fields will be removed after bookworm.
So, having a good account user name is an important thing. And we have
to chose if it should be "good" for the computer (like in: unique,
lowercase, short, US-ASCII, etc.) or if it should be "good" for the
real user. In the latter case, I would accept a broader class of
strings for the very simple reason that it should be left to user
preference.
I checked what other systems do:
Marc Haber, on 2024-11-22:
I might be naive here , but I don't have much experience with non-ascii names since I have the privilege of being fluent in two languages that
use the latin alphabet.
I am not sure whether I am the intended audience here, because
my name is almost Ascii based. That being said, I happen to
have one weird enough latin based character as the first letter
in my first name, that it gives interesting results when thrown
toward random databases. Thus I do happen to have some thoughts
about this topic.
On the other side, wouldnt it be a courtesy to allow people having a
name that needs transcription to be written in latin to use their name
in the real alphabet that it is usually written in as a login name as
well? To make things worse, transcriptions are often ambigious.
I would like to hear the opinion of people who would be affected by this change.
I tried to consider what it would take to have an émollier or an
Émollier login, and there is one little blocker : I may have to
login from environments or keyboards lacking the necessary i18n
and l10n capabilities to transcribe the 'e' acute, let alone the
uppercase 'e' acute.
For example, I hit this particular issue
when populating the Gecos field from the Debian installer
environment: if I choose a Qwerty US configuration but miss the
step to choose which Qwerty US internationalized variant I want
to use, then I don't get to type uppercase 'e' acute, but there
are many other situations unrelated to d-i or even Debian where
I run into that.
For this practical reason, I tend to feel
better about keeping a full Ascii login name. I wouldn't feel
strongly if unicode support for login never happens.
I believe
however that the Gecos is the right place to store the properly
typed-in person name, because it is a "presented" name that
hasn't the technical coupling that the login name has, and I
would probably have stronger feelings if it were to not have
unicode support.
your case highlights another problem not mentioned in the original list posted by Marc: comparison (and normalization).
Some characters can be encoded in more than one way. For instance, "é" in "émollier" could we stored as "e with acute" U+00E9 (and encoded in UTF-8 as 0xc3 0xa9) or as "e, combined with an acute accent" U+0065 plus U+0301 (UTF-8: 0x65 0xcc 0x81).
If a keyboard input system provides the former
sequence of bytes, but the username is stored in the login infrastructure using the latter sequence of bites, then a naive comparison will not find
the user "émollier" in the system.
POSIX says "if you want your applications to be portable, do not use any funny characters in usernames":
A string that is used to identify a user; see also 3.407 User Database.
To be portable across systems conforming to POSIX.1-2024, the value is
composed of characters from the portable filename character set.
Can you outline an attack/failure scenario?
On 24/11/24 10:43, nick black wrote:
Gioele Barabucci left as an exercise for the reader:
On 23/11/24 09:32, Johannes Schauer Marin Rodrigues wrote:
But my 2 cents on the topic are: Lets please allow more than ascii in usernames.
potentially insecure (homographs) and at
high-risk of breaking existing applications (lack of standardized normalization form).
i'm not sure why this is being repeated.
https://unicode.org/reports/tr15/
Dear Nick,
You may have misunderstood that phrase. I was not referring to the fact that there are no standardized normalization forms for Unicode (I explicitly mention Annex 15 in [1]), but to the fact that there is no standard that specifies which of the possible normalization forms should be used for account names (and other fields in passwd).
POSIX explicitly limits itself of a subset of ASCII, so it is not going to mandate any normalization form. Are there other standards (or initiatives)
in this area that you know of?
Regards,
[1] https://lists.debian.org/debian-devel/2024/11/msg00305.html
POSIX explicitly limits itself of a subset of ASCII, so it is not going to >> mandate any normalization form. Are there other standards (or initiatives) >> in this area that you know of?
What about RFC 8265?
"Preparation, Enforcement, and Comparison of Internationalized Strings Representing Usernames and Passwords"
https://datatracker.ietf.org/doc/html/rfc8265
These things are ugly, which is why I suppose they haven't caught on
despite being around for decades, but I would guess that this problem
space is such that there are no non-ugly solutions apart from "just
stick to ASCII", which some people find ugly in a different way.
Apologies if I missed someone bringing up and rejecting Punycode in the previous ~41 messages in this thread.
WTF-8 extends UTF-8 to handle
invalid UTF-16 input.
Marc Haber left as an exercise for the reader:
* any upstream tool could say "bad idea" and refuse patches,
requiring their long term management,
Depending of how important this tool is, we could get away without
patching and probably not even documenting this failure.
This kind of attitude seems self-defeating. Despite being
*strongly* in favor of this effort, I would oppose it if were
strictly a Debian thing. We can inspire the move, but going it
alone seems a recipe for present and future pain (think SSHing
from/to Debian and a non-Debian machine).
* the Linux framebuffer console is pretty limited in what
glyphs it has available, and the number of glyphs it can
support,
Probably, yes. But people working on the Linux framebuffer console are unlikely to actually use UTF-8 user names, so the only really bad
With all due respect, this seems totally unsupported by anything
other than vibes =].
* broken localization (or failure to call setlocale()) could be
a bigger problem, especially for root/system accounts.
I don't think we should allow UTF-8 charactes in the string "root" or in system account names. And if a local admin decides to do so, Debian packages should still restrict themselves to using US-ASCII in their
system accounts.
Why? This would require multiple code paths for what seems to me a
very questionable objective. You point out later in your
response that there already exist diverging codepaths, but isn't
unifying such things always a goal?
Do you have a suggestion for a perl regexp that allows this? My current development directory has "qr/[\p{Graph}*\.\${}><%'@]+/".
I do not. This is not a regex problem in my mind and experience;
you need full access to complicated libraries.
Any such effort
should go through Annex 15 canonicalization before being
inspected at all.
At that point, you're well past regular
languages so far as I can tell. I do not see this goal as
possible with small surgeries on the adduser code base, but
rather something that requires work across the chain.
It cannot. "C" is not UTF-8. Assumption of UTF-8 requires aOur default is C.UTF-8 and has been like that for a while.
properly set LANG and programs calling setlocale(). This, as
alluded to above, has the potential for a big mess.
Yes, but that can be changed.
With all due respect, I admire your gung ho candoit spirit, but
adduser alone is not IMHO the place. This is a major change
requiring support from libraries, applications, and UI to do
right, and thus wide buyin. I love the idea, but it's not going
to happen with a few Perl regexes. Please don't read this as
commentary on you or your code.
But a cursory search shows that none of the current upstreams support (or mention) PRECIS. (It also shows that src:precis is a Java library squatting
a bit on that package name... :))
On Sun, Dec 01, 2024 at 06:55:09PM -0500, nick black wrote:
Marc Haber left as an exercise for the reader:
* any upstream tool could say "bad idea" and refuse patches,
requiring their long term management,
Depending of how important this tool is, we could get away without patching and probably not even documenting this failure.
This kind of attitude seems self-defeating. Despite being
*strongly* in favor of this effort, I would oppose it if were
strictly a Debian thing. We can inspire the move, but going it
alone seems a recipe for present and future pain (think SSHing
from/to Debian and a non-Debian machine).
I bet that other distribtions will also allow me to useradd an UTF-8
name today. I don't think that we have patched useradd to allow this.
On 03/12/24 17:20, Marc Haber wrote:
What I intend to do in adduser for the next unstable upload is:
- adduser --system's user name validation will not change
- I'll make sure that adduser <normal user account> doesn't accept
UTF-8 user names, bringing it closer to systemd's notion of a valid
user name
- adduser --allow-bad-names will still allow UTF-8 usernames, not doing
normalization. I will document this and make it clear that the local
admin needs to make sure that they don't allow things they don't want
to have
Dear Marc,
in preparation for a PRECIS future, couldn't adduser pass the usernames through NFC instead of doing no normalization?
RFC 8264 5.2.4 Normalization Rule states:
In accordance with [RFC5198], Normalization Form C (NFC) is
RECOMMENDED.
What I intend to do in adduser for the next unstable upload is:
- adduser --system's user name validation will not change
- I'll make sure that adduser <normal user account> doesn't accept
UTF-8 user names, bringing it closer to systemd's notion of a valid
user name
- adduser --allow-bad-names will still allow UTF-8 usernames, not doing
normalization. I will document this and make it clear that the local
admin needs to make sure that they don't allow things they don't want
to have
thank you all for your contributions to this discussion. I have now
finally understood¹ that it is not enough to try creating an UTF-8
encoded user name and see that it correctly shows up in /etc/passwd to declare UTF-8 support. Please forgive me for not replying to all of you
in this thread individually, I have read everything and if I didnt cater
for your arguments in this message please feel free to remind me.
I'll probably deprecate --allow-bad-names in favor of something that
doesn't use the word "bad" (suggestions appreciated). Otoh, adduser in
the Red Hat World uses --badname to allow such names as well.
in preparation for a PRECIS future, couldn't adduser pass the usernames
through NFC instead of doing no normalization?
RFC 8264 5.2.4 Normalization Rule states:
In accordance with [RFC5198], Normalization Form C (NFC) is
RECOMMENDED.
that would solve the étienne and étienne issue (where the two characters are just different renderings of the same character), but not the Ohm-against-Omega issue, right?
While this seems the right thing to do, I think this should be done in useradd (pkg:shadow), in the respective upstream project, so that all
Linux distributions get the same behavior.
Marc Haber, on 2024-12-03:
I'll probably deprecate --allow-bad-names in favor of something that doesn't use the word "bad" (suggestions appreciated). Otoh, adduser in
the Red Hat World uses --badname to allow such names as well.
The problem is not the name, but the character set, so perhaps --allow-bad-characters will be better perceived. If you want to
also avoid "bad", maybe try --allow-ambiguous-characters, or --allow-extended-character-set? The last one is perhaps a bit
long winded, but also sounds more accurate than the rest. What
do you think of these approaches?
On 03/12/24 17:59, Marc Haber wrote:
in preparation for a PRECIS future, couldn't adduser pass the usernames through NFC instead of doing no normalization?
RFC 8264 5.2.4 Normalization Rule states:
In accordance with [RFC5198], Normalization Form C (NFC) is
RECOMMENDED.
that would solve the étienne and étienne issue (where the two characters are just different renderings of the same character), but not the Ohm-against-Omega issue, right?
NFC would solve both of these "problems":
* Both U+00E9 (é) and U+0065, U+0301 are NFC-normalized to U+00E9,
* Both U+2126 (Ohm sign) and U+0349 (omega) are NFC-normalized to U+0349 (omega).
Thanks for taking the time to delve into this issue,
On Tue, Dec 03, 2024 at 08:41:06PM +0100, Étienne Mollier wrote:
The problem is not the name, but the character set, so perhaps --allow-bad-characters will be better perceived. If you want to
also avoid "bad", maybe try --allow-ambiguous-characters, or --allow-extended-character-set? The last one is perhaps a bit
long winded, but also sounds more accurate than the rest. What
do you think of these approaches?
Extended sounds good, maybe even "unicode"? or "international"?
Normalization is always lossy, at least in principle.
Applications that employ normalization accept that tradeoff in order to gain something valuable: in this case the ability to have a Ohm sign codepoint as part of your username is traded for the ability to compare usernames across different OSes and applications.
On Tue, Dec 03, 2024 at 09:39:03PM +0100, Gioele Barabucci wrote:
On 03/12/24 17:59, Marc Haber wrote:
in preparation for a PRECIS future, couldn't adduser pass the usernames >>>> through NFC instead of doing no normalization?
RFC 8264 5.2.4 Normalization Rule states:
In accordance with [RFC5198], Normalization Form C (NFC) is
RECOMMENDED.
that would solve the étienne and étienne issue (where the two characters >>> are just different renderings of the same character), but not the
Ohm-against-Omega issue, right?
NFC would solve both of these "problems":
* Both U+00E9 (é) and U+0065, U+0301 are NFC-normalized to U+00E9,
* Both U+2126 (Ohm sign) and U+0349 (omega) are NFC-normalized to U+0349
(omega).
Converting Ohm into an Omega is losing intended information, isnt it?
Hi,
thank you all for your contributions to this discussion. I have now
finally understood¹ that it is not enough to try creating an UTF-8
encoded user name and see that it correctly shows up in /etc/passwd to declare UTF-8 support. Please forgive me for not replying to all of you
in this thread individually, I have read everything and if I didnt cater
for your arguments in this message please feel free to remind me.
https://lists.debian.org/debian-devel/2024/11/msg00491.html correctly outlines that homograph characters (such as é (UTF-8 0xC3 0xA9 and the lookalike é 0x65 0xCC 0x81) are not only a nuisance. At the least,
adduser should reject creating étienne if étienne already exists - those are different user names but look the same, and if you don't
cut-and-paste user names instead of typing them you're bound to hit the
wrong user depending on HOW you type and what input medium you use. Not
good.
https://wiki.debian.org/UserAccounts and https://wiki.debian.org/UserAccountsPhilosophy are updated accordingly.
After understanding this, I must admit that what's currently left active
on the adduser team (me) doesn't have the capacity to implement this
properly and in time for trixie. To make things worse, the
Unicode::Precis module, which should be in Debian as
libunicode-precis-perl (but isn't) hasnt seen an upstream release in
more than five years.
Additionally, I don't see myself in the situation of writing a proper
checker for the RFC 8264 IdentifierClass (Chapter 4.2) at the moment
since I don't have the time to check out which \p{Foo} character classes match the classes given in the RFC.
I would appreciate volunteers to help here, but first I need to bring
some sense in adduser's current state of affairs to make an unstable
upload that can eventuall migrate to testing.
What I intend to do in adduser for the next unstable upload is:
- adduser --system's user name validation will not change
- I'll make sure that adduser <normal user account> doesn't accept
UTF-8 user names, bringing it closer to systemd's notion of a valid
user name
- adduser --allow-bad-names will still allow UTF-8 usernames, not doing
normalization. I will document this and make it clear that the local
admin needs to make sure that they don't allow things they don't want
to have
- adduser --allow-all-names will just verbatim pass all user names to
useradd.
All this will be documented in the man page, in README.Debian and/or the
Wiki after the code passes the test suite again.
I'll probably deprecate --allow-bad-names in favor of something that
doesn't use the word "bad" (suggestions appreciated). Otoh, adduser in
the Red Hat World uses --badname to allow such names as well.
I would love to hear your opinion. Silence is agreement ;-)
Greetings
Marc
¹ RFC 8264, RFC 8265, and Unicode TR 15 linked in this thread were
educating for me
Homograph attacks would be best mitigated in software reading
/etc/passwd, alerting in their output or logs that the user name they
just printed was composed of strange alphabets.
On Tue, Dec 03, 2024 at 08:41:06PM +0100, Étienne Mollier wrote:
Marc Haber, on 2024-12-03:
I'll probably deprecate --allow-bad-names in favor of something that doesn't use the word "bad" (suggestions appreciated). Otoh, adduser in the Red Hat World uses --badname to allow such names as well.
The problem is not the name, but the character set, so perhaps --allow-bad-characters will be better perceived. If you want to
also avoid "bad", maybe try --allow-ambiguous-characters, or --allow-extended-character-set? The last one is perhaps a bit
long winded, but also sounds more accurate than the rest. What
do you think of these approaches?
Extended sounds good, maybe even "unicode"? or "international"?
The best mitigation for those attacks is to ban the names altogether.
IMO, setuid programs should not accept Unicode.
The best mitigation for those attacks is to ban the names altogether.
IMO, setuid programs should not accept Unicode.
Neither adduser nor useradd are setuid.
I recommend Chapter 7 of my free book, "Hacking the Planet with
Notcurses: A Guide to TUIs and Character Semigraphics" for the
full story (as I understand it) regarding Unicode presentation: https://nick-black.com/htp-notcurses.pdf (starts on page 41).
On Tue, Dec 03, 2024 at 08:41:06PM +0100, Étienne Mollier wrote:
Marc Haber, on 2024-12-03:
I'll probably deprecate --allow-bad-names in favor of something that doesn't use the word "bad" (suggestions appreciated). Otoh, adduser in the Red Hat World uses --badname to allow such names as well.
The problem is not the name, but the character set, so perhaps --allow-bad-characters will be better perceived. If you want to
also avoid "bad", maybe try --allow-ambiguous-characters, or --allow-extended-character-set? The last one is perhaps a bit
long winded, but also sounds more accurate than the rest. What
do you think of these approaches?
Extended sounds good, maybe even "unicode"? or "international"?
P.S.: Sadly, this has gotten less than positive coverage on LWN. I
apologize for the harm this discussion has done.
This was never on the table, and shadow upstream might even drop the
entire "support" for having bad names.
On Mon, 9 Dec 2024 18:08:33 +0100, Chris Hofstaedtler
<zeha@debian.org> wrote:
I echo Alejandro's concerns. We should stop having the flag
completely, not encourage using it.
I violently disagree. But I have to accept this.
IOW: if we move towards better character support, we need to do that
by allowing it always. Same for longer names.
I think that our distinction between system users and "normal" users
is fine. Noone needs a package generating "weird" user names.
NFC would solve both of these "problems":
* Both U+00E9 (é) and U+0065, U+0301 are NFC-normalized to U+00E9,
* Both U+2126 (Ohm sign) and U+0349 (omega) are NFC-normalized to U+0349 (omega).
What NFC alone will not solve are homograph collisions: a (U+0061 Latin
small letter a) and а (U+0430 Cyrillic small letter a) are NFC-normalized to different codepoints.
But these are two different scenarios: the former problem may (and does) arise without any wrongdoing from the user's side (a different OS, or a different string manipulation library, or a screen keyboard may produce a different é), the latter is an attack. The former is an interoperability issue, the latter is a security issue.
While this seems the right thing to do, I think this should be done in useradd (pkg:shadow), in the respective upstream project, so that all
Linux distributions get the same behavior.
That's probably the best approach.
Thanks for taking the time to delve into this issue,
--
Gioele Barabucci
On Tue, Dec 03, 2024 at 09:39:03PM +0100, Gioele Barabucci wrote:
NFC would solve both of these "problems":
* Both U+00E9 (é) and U+0065, U+0301 are NFC-normalized to U+00E9,
* Both U+2126 (Ohm sign) and U+0349 (omega) are NFC-normalized to U+0349
(omega).
What NFC alone will not solve are homograph collisions: a (U+0061 Latin
small letter a) and а (U+0430 Cyrillic small letter a) are NFC-normalized to
different codepoints.
NFC also doesn't solve various invisible characters (e.g., zero-width
spaces, bidirectional control characters). For more information about
all of the various security land mines, see[1].
NFC has been mentioned in a broader discussion on PRECIS/RFC8264/RFC8265.
The IdentifierClass of RFC 8264 explicitly disallows all these "security
land mines": https://www.rfc-editor.org/rfc/rfc8264.html#section-4.2.3
The "Security considerations" section is quite extensive (5 pages long): https://www.rfc-editor.org/rfc/rfc8264.html#section-12
To me, the question is more, why do we have a flag that, if used,
allows you to break /etc/{passwd,shadow,group,gshadow} completely?
However, it should be noted that RFC 8264 also states that code points
which are not defined in whatever version of the Unicode supported by
"the application" shall be disallowed. From Debian's perspective,
though, if we are going to take a position about what version of
Unicode should be supported by "the application(s)" that read and
write /etc/passwd, we *will* need to take a position on what version
of Unicode should be supported, and therefore, what set of characters
will be disallowed.
I would involve cross-distribution discussion about this though.
Perhaps the /etc/passwd APIs affect some POSIX specifications, and a non-ASCII extension could be proposed.
Yeah, good point. If the scope is going to include passwd entries
that are distributed via network protocols like LDAP, then we need to
worry about sites that support other Linux distributions beyond just
Debian --- or for that matter, sites that need to support Linux as
well as legacy Unix systems like AIX or Solaris.
is there an easy way to determine for a given Unicode string if it[...]
can be typed from a single keboard layout
sorry if it is too naive, but is there an easy way to determine for a
given Unicode string if it can be typed from a single keboard layout or >produced by a text-to-speech system? People who want a username because
of SSH, email and su will want to be able to input it.
But things are moving by shadow upstream taking a user-hostile stance, willing to take away freedom. I must be fine with that because I
cannot change it. But I don't need to like it.
That's easy, just choose a user name for YOU that YOU can type on YOUR keyboard. Why would anybody chose a username that is impossible to use
in their own locale?
I don't see much problems with single-user machines, especially security related. But, think multi-user environments? Imagine, as a non-Chinese speaking Westerner, needing to chown a file to a colleague called 陈成.
On Tue, Dec 10, 2024 at 09:24:15PM +0100, Marc Haber wrote:
But things are moving by shadow upstream taking a user-hostile stance,
willing to take away freedom. I must be fine with that because I
cannot change it. But I don't need to like it.
As a suggestion, we might make more forward progress if we assume good
faith and accept that other people might have different priorities
than others. I could easily see shadow, being a security-related
package, would consider encouraging something that could lead to
security bugs or just other random breakage, as "user-hostile".
Perhaps at some future stable Debian release (not Trixie), we could
enable it by default.
I don't see much problems with single-user machines, especially security >related. But, think multi-user environments? Imagine, as a non-Chinese >speaking Westerner, needing to chown a file to a colleague called 陈成. Even
I don’t need non-ASCII for my name but I would never use a system that would forces me to rewrite my name in ASCII because it is so utterly broken in 2024. I bet there is no problem on Windows systems.
Stephan
consisting entirely of Windows(basics), PowerPoint, Word and Excel; but >that's another story), and *of course* all usernames have been
normalized to lowercase ASCII.
They are planning to remove the --badname option from useradd, making
it impossible to even try UTF-8 user names, without patching useradd.
and *of course* all usernames have been normalized to lowercase ASCII.
On Fri, Dec 13, 2024 at 10:08:19AM -0500, Michael Stone wrote:
On Fri, Dec 13, 2024 at 12:22:38PM +0100, Marc Haber wrote:
They are planning to remove the --badname option from useradd, making
it impossible to even try UTF-8 user names, without patching useradd.
Or edit the passwd file (vipw), or use any non-passwd-file authentication mechanism, or use a different user management tool, etc.
I think you're overemphasizing the importance of the useradd command here--it just acts as a convenience and sets some baseline policies;
it's not actually essential for adding a user. If you don't like the policy that useradd sets...just don't use it.
In the context of the whole thread, are you suggesting that adduser(1)
should be changed to use something other than useradd(8) under the hood?
On Fri, Dec 13, 2024 at 12:22:38PM +0100, Marc Haber wrote:
They are planning to remove the --badname option from useradd, making
it impossible to even try UTF-8 user names, without patching useradd.
Or edit the passwd file (vipw), or use any non-passwd-file authentication mechanism, or use a different user management tool, etc.
I think you're overemphasizing the importance of the useradd command
here--it just acts as a convenience and sets some baseline policies;
it's not actually essential for adding a user. If you don't like the policy that useradd sets...just don't use it.
In the context of the whole thread, are you suggesting that adduser(1)
should be changed to use something other than useradd(8) under the hood?
On Fri, Dec 13, 2024 at 10:08:19AM -0500, Michael Stone wrote:
On Fri, Dec 13, 2024 at 12:22:38PM +0100, Marc Haber wrote:
They are planning to remove the --badname option from useradd, making
it impossible to even try UTF-8 user names, without patching useradd.
Or edit the passwd file (vipw), or use any non-passwd-file authentication
mechanism, or use a different user management tool, etc.
I think you're overemphasizing the importance of the useradd command
here--it just acts as a convenience and sets some baseline policies;
it's not actually essential for adding a user. If you don't like the policy >> that useradd sets...just don't use it.
In the context of the whole thread, are you suggesting that adduser(1)
should be changed to use something other than useradd(8) under the hood?
getent passwd 1144💩:*:1144:1144::/nowhere:/bin/false
getent group 1144💩:*:1144:
ls -l /tmp/samplefile-rw-r--r-- 1 💩 💩 0 Dec 13 22:42 /tmp/samplefile
On Fri, Dec 13, 2024 at 07:00:36PM +0200, Peter Pentchev wrote:[snip more about adding accounts without useradd/adduser]
On Fri, Dec 13, 2024 at 10:08:19AM -0500, Michael Stone wrote:
On Fri, Dec 13, 2024 at 12:22:38PM +0100, Marc Haber wrote:
They are planning to remove the --badname option from useradd, making it impossible to even try UTF-8 user names, without patching useradd.
Or edit the passwd file (vipw), or use any non-passwd-file authentication mechanism, or use a different user management tool, etc.
I think you're overemphasizing the importance of the useradd command here--it just acts as a convenience and sets some baseline policies;
it's not actually essential for adding a user. If you don't like the policy
that useradd sets...just don't use it.
In the context of the whole thread, are you suggesting that adduser(1) should be changed to use something other than useradd(8) under the hood?
No, I'm suggesting that rhetoric asserting that any adduser/useradd policy could constrain people is overblown because users can be added to the system without using either of those tools. The tools' policies should reflect what is safest and most sensible for the majority of users, but if someone wants to do something different there is nothing stopping them from doing so.
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 546 |
| Nodes: | 16 (1 / 15) |
| Uptime: | 160:37:10 |
| Calls: | 10,385 |
| Calls today: | 2 |
| Files: | 14,056 |
| Messages: | 6,416,493 |
{kind=link}