there are quite many Linux users who never used a terminal.
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
About this, I have another question. Some of my family use Macs, not Windows PCs. Am I right in thinking that, since recent versions of
MacOS are Linux based,
they should be able to run this shell script to
achieve what those using Windows will be able to do with the BATch file?
Do I have to give them any special instructions, for example how to
get into a console?
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
About this, I have another question. Some of my family use Macs, not Windows PCs. Am I right in thinking that, since recent versions of
MacOS are Linux based,
they should be able to run this shell script to
achieve what those using Windows will be able to do with the BATch file?
Do I have to give them any special instructions, for example how to
get into a console?
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
then
# Do processing
fi
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
I had the same problem in the Windows BATch version of the script, which
I fixed by changing the codepage to ANSI 1252 before doing the
processing in the script, and then changing it back when it was
finished. The Windows BATch program now works perfectly.
I now need something similar for the Linux shell script.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
... I get the following error:
<script name>: line ###: syntax error near unexpected token '-f'
<script name>: line ###: done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
So next I tried ...
done < $(iconv -f 'CP1252' -t 'UTF-8' "${DATA}")
... but this gives ...
<script name>: line ###: done < iconv -f 'CP1252' -t 'UTF-8'
"${DATA}": ambiguous redirect
What is is the correct incantational magic to achieve what I want?
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
there are quite many Linux users who never used a terminal.
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
Assuming that the example code above is really what you want then
iconv -f 'CP1252' -t 'UTF-8' "${DATA}" | while read LINE ; do
if [ -z "${LINE}" ] ; then break ; fi
# Do processing
done
On Fri, 13 Aug 2021 21:37:38 -0000 (UTC)
Jasen Betts <usenet@revmaps.no-ip.org> wrote:
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
I think it should be
done < <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
On Fri, 13 Aug 2021 20:28:07 +0100
Java Jive <java@evij.com.invalid> wrote:
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
There is a double quote missing in the previous line.
then
# Do processing
fi
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
Just to be clear , the above loop will exit at the first empty line read
from $DATA even though the file may have more (possibly non empty) lines after that. Is this what you want ? It seems doubtful because you also have the test if [ -n "${LINE} ] .
What is is the correct incantational magic to achieve what I want?
Assuming that the example code above is really what you want then
iconv -f 'CP1252' -t 'UTF-8' "${DATA}" | while read LINE ; do
if [ -z "${LINE}" ] ; then break ; fi
# Do processing
done
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
then
# Do processing
fi
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
I had the same problem in the Windows BATch version of the script, which
I fixed by changing the codepage to ANSI 1252 before doing the
processing in the script, and then changing it back when it was
finished. The Windows BATch program now works perfectly.
I now need something similar for the Linux shell script.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
... I get the following error:
<script name>: line ###: syntax error near unexpected token '-f'
<script name>: line ###: done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
So next I tried ...
done < $(iconv -f 'CP1252' -t 'UTF-8' "${DATA}")
... but this gives ...
<script name>: line ###: done < iconv -f 'CP1252' -t 'UTF-8'
"${DATA}": ambiguous redirect
What is is the correct incantational magic to achieve what I want?
On Fri, 13 Aug 2021 21:37:38 -0000 (UTC)
Jasen Betts <usenet@revmaps.no-ip.org> wrote:
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
I think it should be
done < <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
Assuming that the example code above is really what you want then
iconv -f 'CP1252' -t 'UTF-8' "${DATA}" | while read LINE ; do
if [ -z "${LINE}" ] ; then break ; fi
# Do processing
done
J.O. Aho wrote:
there are quite many Linux users who never used a terminal.
Many linux users who are *almost* exclusively graphical often find
support in the form of a command someone gives them which they then
paste into the terminal, because communicating a solution by a problem
solver is very frequently much easier by way of a command even if there
is a graphical route to the same solution.
Correct, a typo while I was transposing from the screen of the Linux PC,
the original script file is correct.
On 2021-08-14, Spiros Bousbouras <spibou@gmail.com> wrote:
On Fri, 13 Aug 2021 21:37:38 -0000 (UTC)
Jasen Betts <usenet@revmaps.no-ip.org> wrote:
On 2021-08-13, Java Jive <java@evij.com.invalid> wrote:
done < "${DATA}"
... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e >>>> umlaut needs to be moved to a new location and given a new name.
If I replace the 'done' line with ...
done < iconv -f 'CP1252' -t 'UTF-8' "${DATA}"
you want this:
done <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
I think it should be
done < <( iconv -f 'CP1252' -t 'UTF-8' "${DATA}" )
You're right!
J.O. Aho wrote:
there are quite many Linux users who never used a terminal.
Many linux users who are *almost* exclusively graphical often find
support in the form of a command someone gives them which they then
paste into the terminal, because communicating a solution by a problem
solver is very frequently much easier by way of a command even if there
is a graphical route to the same solution.
Correct, a typo while I was transposing from the screen of the Linux PC,
the original script file is correct.
About this, I have another question. Some of my family use Macs, not Windows PCs. Am I right in thinking that, since recent versions of
MacOS are Linux based, they should be able to run this shell script to
achieve what those using Windows will be able to do with the BATch
file? Do I have to give them any special instructions, for example how
to get into a console?
On Sat, 14 Aug 2021 02:35:18 +0100, Java Jive wrote:
Copy & Paste:
Correct, a typo while I was transposing from the screen of the Linux PC,
the original script file is correct.
- highlight text in a window on the desk top
- hit then Ctrl-C to copy
- hit Ctrl-V to paste into (another) window open on the desktop
avoids typos (works for XFCE and, I assume, for all other Linux graphical desktops.
and was created on a Windows machine,
Mike Easter wrote:
J.O. Aho wrote:
there are quite many Linux users who never used a terminal.
Many linux users who are *almost* exclusively graphical often find
support in the form of a command someone gives them which they then
paste into the terminal, because communicating a solution by a problem
solver is very frequently much easier by way of a command even if
there is a graphical route to the same solution.
You are assuming that people always has problem with their Linux installation, I do personally know people who never used the terminal at
all. Linux has evolved quite a lot since the 1990's.
I'm not trying to infer that linux is full of problems that need
commands to solve;
J.O. Aho wrote:
You are assuming that people always has problem with their Linux installation, I do personally know people who never used the
terminal at all. Linux has evolved quite a lot since the 1990's.
I can't deny that you know people who have never used the terminal;
I'm just asserting that graphically-oriented linux users are
frequently advised to accomplish a *necessary* task using the command
line.
For example, there have been discussions here about how the most
standard way of instructing people how to authenticate their linux
.iso download is by way of a command.
I'm not trying to infer that linux is full of problems that need
commands to solve; I'm asserting that the easiest way to instruct
someone how to DO something, problem or not, is often conveyed by way
of a command *because* conveying instructions by way of a command is
very VERY often the most efficient and clear way to convey the
information.
Sometimes one would practically need a vid to show a graphical route
to do something relatively simple which can be expressed as a command
in a line or two. Lord knows we don't need more vid/s on the planet
:-)
Mike Easter wrote:
J.O. Aho wrote:
there are quite many Linux users who never used a terminal.
Many linux users who are *almost* exclusively graphical often find
support in the form of a command someone gives them which they then
paste into the terminal, because communicating a solution by a problem
solver is very frequently much easier by way of a command even if
there is a graphical route to the same solution.
You are assuming that people always has problem with their Linux installation, I do personally know people who never used the terminal at
all. Linux has evolved quite a lot since the 1990's.
J.O. Aho wrote:
You are assuming that people always has problem with their Linux installation, I do personally know people who never used the
terminal at all. Linux has evolved quite a lot since the 1990's.
I can't deny that you know people who have never used the terminal;
I'm just asserting that graphically-oriented linux users are
frequently advised to accomplish a *necessary* task using the command
line.
For example, there have been discussions here about how the most
standard way of instructing people how to authenticate their linux
.iso download is by way of a command.
I'm not trying to infer that linux is full of problems that need
commands to solve; I'm asserting that the easiest way to instruct
someone how to DO something, problem or not, is often conveyed by way
of a command *because* conveying instructions by way of a command is
very VERY often the most efficient and clear way to convey the
information.
Sometimes one would practically need a vid to show a graphical route
to do something relatively simple which can be expressed as a command
in a line or two. Lord knows we don't need more vid/s on the planet
:-)
and was created on a Windows machine,
I'm not trying to infer that linux is full of problems that need
commands to solve;
I can't deny that you know people who have never used the terminal; I'm
just asserting that graphically-oriented linux users are frequently
advised to accomplish a *necessary* task using the command line.
For example, there have been discussions here about how the most
standard way of instructing people how to authenticate their linux .iso download is by way of a command.
while you're sorting out their immediate problem, I hope
you'd also tell them how to use 'apropos' and 'man', if only because that
can short circuit a lot of future hand-holding.
If the student is capable of using command lines on another system,
then something like 'Linux in a Nutshell' may be helpful, but that's
about the only decent book I know unless there's a 'Linux for
Dummies' available and they're not put off by the title.
Martin Gregorie wrote:
while you're sorting out their immediate problem, I hope you'd also
tell them how to use 'apropos' and 'man', if only because that can
short circuit a lot of future hand-holding.
Those two commands are excellent examples of how much there is for the inexperienced to learn about commands, namely how to use the options for commands.
That 'problem' (actually *strength*) is one of the intimidating factors
for the less experienced in terms of commands, namely options and
syntax.
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
Of course, being thrown into the water and needing to swim back out is
one way to learn to swim :-)
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
Martin Gregorie wrote:The other thing that needs to be taught is that each command is designed
while you're sorting out their immediate problem, I hope you'd also
tell them how to use 'apropos' and 'man', if only because that can
short circuit a lot of future hand-holding.
Those two commands are excellent examples of how much there is for the
inexperienced to learn about commands, namely how to use the options for
commands.
That 'problem' (actually *strength*) is one of the intimidating factors
for the less experienced in terms of commands, namely options and
syntax.
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
to do one thing and to do it well, which is why there are so *many*
commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out is.. and sadly there isn't a lot else. If the student is capable of using command lines on another system, then something like 'Linux in a
one way to learn to swim :-)
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off by
the title.
I head for books every time, but then my background is not altogether
usual. I arrived at Linux via:
- being taught to run an ICL 1900 mainframe using the control teletype
and to program it in Algol 60, assembler and COBOL, running under both
George2 and George 3
- another job with formal training got me up to speed on ICL 2966
mainframes running VME/B, COBOL (again) and IDMSX database
- after that I worked for software houses, were the style was very much
"What, you've heard of it[*]? Just the man: here are the manuals and
you'll be on the project team in a week."
[*] 'it' might be a new programming language, database, operating
system, hardware or some combination of all of four. Fun times!
while you're sorting out their immediate problem, I hope
you'd also tell them how to use 'apropos' and 'man', if only because that
can short circuit a lot of future hand-holding.
I can't deny that you know people who have never used the terminal; I'm
just asserting that graphically-oriented linux users are frequently
advised to accomplish a *necessary* task using the command line.
For example, there have been discussions here about how the most
standard way of instructing people how to authenticate their linux .iso download is by way of a command.
Martin Gregorie wrote:
while you're sorting out their immediate problem, I hope you'd also
tell them how to use 'apropos' and 'man', if only because that can
short circuit a lot of future hand-holding.
Those two commands are excellent examples of how much there is for the inexperienced to learn about commands, namely how to use the options for commands.
That 'problem' (actually *strength*) is one of the intimidating factors
for the less experienced in terms of commands, namely options and
syntax.
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
Of course, being thrown into the water and needing to swim back out is
one way to learn to swim :-)
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
Martin Gregorie wrote:The other thing that needs to be taught is that each command is designed
while you're sorting out their immediate problem, I hope you'd also
tell them how to use 'apropos' and 'man', if only because that can
short circuit a lot of future hand-holding.
Those two commands are excellent examples of how much there is for the
inexperienced to learn about commands, namely how to use the options for
commands.
That 'problem' (actually *strength*) is one of the intimidating factors
for the less experienced in terms of commands, namely options and
syntax.
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
to do one thing and to do it well, which is why there are so *many*
commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out is.. and sadly there isn't a lot else. If the student is capable of using command lines on another system, then something like 'Linux in a
one way to learn to swim :-)
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off by
the title.
I head for books every time, but then my background is not altogether
usual. I arrived at Linux via:
- being taught to run an ICL 1900 mainframe using the control teletype
and to program it in Algol 60, assembler and COBOL, running under both
George2 and George 3
- another job with formal training got me up to speed on ICL 2966
mainframes running VME/B, COBOL (again) and IDMSX database
- after that I worked for software houses, were the style was very much
"What, you've heard of it[*]? Just the man: here are the manuals and
you'll be on the project team in a week."
[*] 'it' might be a new programming language, database, operating
system, hardware or some combination of all of four. Fun times!
If the student is capable of using command lines on another system,
then something like 'Linux in a Nutshell' may be helpful, but that's
about the only decent book I know unless there's a 'Linux for
Dummies' available and they're not put off by the title.
Unfortunately man is really good for reminding someone what various
things mean, but is pretty bad at teaching anyone how to use the
command. A much much larger section for each man page with explicity
examples would go a long way to making "man" useful for newbies (and
oldies as well).
Says someone, apparently, who has never looked at the command "find", or
may other commands. billions of different option combinations, some of
which work, others of which do not.
Says someone, apparently, who has never looked at the command "find", or
may other commands. billions of different option combinations, some of
which work, others of which do not.
Unfortunately man is really good for reminding someone what various
things mean, but is pretty bad at teaching anyone how to use the
command. A much much larger section for each man page with explicity
examples would go a long way to making "man" useful for newbies (and
oldies as well).
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
The other thing that needs to be taught is that each command is designed
to do one thing and to do it well, which is why there are so *many*
commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out is
one way to learn to swim :-)
.. and sadly there isn't a lot else. If the student is capable of using command lines on another system, then something like 'Linux in a
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off by
the title.
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find", or
may other commands. billions of different option combinations, some of
which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and easier
to use, especially if updatedb is run overnight by a cronjob
On Sat, 14 Aug 2021 22:52:08 +0000, William Unruh wrote:
Says someone, apparently, who has never looked at the command "find", orQuite right: I don't use it because 'locate' is *much* faster and easier
may other commands. billions of different option combinations, some of
which work, others of which do not.
to use, especially if updatedb is run overnight by a cronjob
Similarly, 'apropos' is nearly as fast 'locate' since it only has to scan
the contents of /usr/share/man/* - and in addition, because its scanning
the first line of each manpage, it also matches words of phrases
describing what a program does, so often searching on a word or phrase describing what a program does means you a suitable program without
knowing its name:
$ apropos 'free space'
e2freefrag (8) - report free space fragmentation information xfs_spaceman (8) - show free space information about an XFS filesystem
$ apropos 'space used'
space used: nothing appropriate.
$ apropos 'space usage'
df (1) - report file system disk space usage
du (1) - estimate file space usage
du (1p) - estimate file space usage
... and its no use complaining about how well or badly a manpage is
written: often the only way to fit would be to submit a manpage patch.
Yes, I know some Linux manpages are pretty bad. However, others (those
for bash, sort and awk to name but a few) are excellent and most are
usable.
<sf9afk$q7c$1@dont-email.me>On Sat, 14 Aug 2021 20:53:08 -0000 (UTC)
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
The commands were designed to be very powerful; the greater the power
the greater the 'responsibility'. Sometimes when one sees a man result
he feels like he is drowning.
The other thing that needs to be taught is that each command is designed
to do one thing and to do it well, which is why there are so *many*
commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out is
one way to learn to swim :-)
.. and sadly there isn't a lot else. If the student is capable of using command lines on another system, then something like 'Linux in a
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off by
the title.
On Sat, 14 Aug 2021 22:52:08 +0000, William Unruh wrote:
Says someone, apparently, who has never looked at the command "find", orQuite right: I don't use it because 'locate' is *much* faster and easier
may other commands. billions of different option combinations, some of
which work, others of which do not.
to use, especially if updatedb is run overnight by a cronjob
Similarly, 'apropos' is nearly as fast 'locate' since it only has to scan
the contents of /usr/share/man/* - and in addition, because its scanning
the first line of each manpage, it also matches words of phrases
describing what a program does, so often searching on a word or phrase describing what a program does means you a suitable program without
knowing its name:
$ apropos 'free space'
e2freefrag (8) - report free space fragmentation information xfs_spaceman (8) - show free space information about an XFS filesystem
$ apropos 'space used'
space used: nothing appropriate.
$ apropos 'space usage'
df (1) - report file system disk space usage
du (1) - estimate file space usage
du (1p) - estimate file space usage
... and its no use complaining about how well or badly a manpage is
written: often the only way to fit would be to submit a manpage patch.
Yes, I know some Linux manpages are pretty bad. However, others (those
for bash, sort and awk to name but a few) are excellent and most are
usable.
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
then
# Do processing
fi
done < "${DATA}"
.... and this works fine for all but two lines in the data file, which contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
Richard Kettlewell wrote:
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command
"find", or may other commands. billions of different option
combinations, some of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
Both look for filenames,
but 'find' can be restricted to a directory structure - thats about
the difference I can see in a quick manpage scan.
Now the crunch, when I unzip these on a Linux machine, I see different bastardisations of accented characters. So, for example where the full
7zip archive when extracted shows an e acute correctly in both a console
and a file manager listing ...
"Chat Botté, Le" [e is correctly acute]
... (if you're wondering, a French children's picture book version of apparently 'Puss In Boots'), while with the WinZip main archive a
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
... and a file manager listing has a graphic character resembling a 2x2 matrix, concerning which note that while \302 octal = \xC2 hex, and
\202 octal = \x82 hex, only the second of these and not the first
appears in the symbol:
|00|
|82|
My problem is that I can't find a search term to trap this strange
character to correct it, for example the following, and a few similar
that I've tried, don't work because they don't find the directory:
mv "Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
mv Chat\ Bott\'$\'\\302\\202\'\',\ Le "Chat Botté, Le"
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find",
or may other commands. billions of different option combinations, some
of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
On Sat, 14 Aug 2021 20:53:08 -0000 (UTC)
Martin Gregorie <martin@mydomain.invalid> wrote:
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
The commands were designed to be very powerful; the greater the powerThe other thing that needs to be taught is that each command is
the greater the 'responsibility'. Sometimes when one sees a man
result he feels like he is drowning.
designed to do one thing and to do it well, which is why there are so
*many* commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out.. and sadly there isn't a lot else. If the student is capable of using
is one way to learn to swim :-)
command lines on another system, then something like 'Linux in a
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off
by the title.
If I go on amazon and search for "Linux command line" I see many books
and they tend to have high rating average. Either you don't consider
them decent or you haven't performed any such search in a long time even
just for curiosity.
On 2021-08-14, Martin Gregorie <martin@mydomain.invalid> wrote:
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
Unfortunately man is really good for reminding someone what various
things mean, but is pretty bad at teaching anyone how to use the
command. A much much larger section for each man page with explicity
examples would go a long way to making "man" useful for newbies (and
oldies as well).
Martin Gregorie wrote:
On Sat, 14 Aug 2021 22:52:08 +0000, William Unruh wrote:
Says someone, apparently, who has never looked at the command "find", or >>> may other commands. billions of different option combinations, some ofQuite right: I don't use it because 'locate' is *much* faster and
which work, others of which do not.
easier to use, especially if updatedb is run overnight by a cronjob
Similarly, 'apropos' is nearly as fast 'locate' since it only has to
scan the contents of /usr/share/man/* - and in addition, because its
scanning the first line of each manpage, it also matches words of
phrases describing what a program does, so often searching on a word
or phrase describing what a program does means you a suitable program
without knowing its name:
$ apropos 'free space'
e2freefrag (8) - report free space fragmentation information
xfs_spaceman (8) - show free space information about an XFS
filesystem
$ apropos 'space used'
space used: nothing appropriate.
$ apropos 'space usage'
df (1) - report file system disk space usage
du (1) - estimate file space usage
du (1p) - estimate file space usage
... and its no use complaining about how well or badly a manpage is
written: often the only way to fit would be to submit a manpage patch.
Yes, I know some Linux manpages are pretty bad. However, others (those
for bash, sort and awk to name but a few) are excellent and most are
usable.
This is why you keep a "notes" file.
find /media/somedisk -type d -exec ls -al -1 -d {} + > directories.txt
find /media/somedisk -type f -exec ls -al -1 {} + > filelist.txt
Any time you put some effort into crafting one, you
record it for the future.
./ffmpeg -hwaccel nvdec -i "fedora.mkv" -y -acodec aac -vcodec
h264_nvenc -crf 23 "output2.mp4"
16.3x speed, 488FPS
Part of the fun is making them cryptic, so you can't understand them later.
Paul
On Sun, 15 Aug 2021 12:57:24 +0100
Java Jive <java@evij.com.invalid> wrote:
Now the crunch, when I unzip these on a Linux machine, I see different
bastardisations of accented characters. So, for example where the full
7zip archive when extracted shows an e acute correctly in both a console
and a file manager listing ...
"Chat Botté, Le" [e is correctly acute]
... (if you're wondering, a French children's picture book version of
apparently 'Puss In Boots'), while with the WinZip main archive a
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
... and a file manager listing has a graphic character resembling a 2x2
matrix, concerning which note that while \302 octal = \xC2 hex, and
\202 octal = \x82 hex, only the second of these and not the first
appears in the symbol:
|00|
|82|
You aren't going to get anywhere with using high level tools for this. You need to go low level and see the values of the actual bytes in the filenames. So for example something like
ls *Chat* | od -A n -t x1
which will show the bytes in hexadecimal.
My problem is that I can't find a search term to trap this strange
character to correct it, for example the following, and a few similar
that I've tried, don't work because they don't find the directory:
mv "Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
mv Chat\ Bott\'$\'\\302\\202\'\',\ Le "Chat Botté, Le"
What directory ? Your post says that some files have strange names. Do also some directories have strange names ? In any case , the commands above do not show a directory separator.
On 15/08/2021 13:58, Spiros Bousbouras wrote:
You aren't going to get anywhere with using high level tools for this.
You
need to go low level and see the values of the actual bytes in the
filenames.
So for example something like
ls *Chat* | od -A n -t x1
which will show the bytes in hexadecimal.
Thanks again, will look into that.
On Sun, 15 Aug 2021 08:37:45 +0100, Richard Kettlewell wrote:
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find",
or may other commands. billions of different option combinations, some >>>> of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
Both look for filenames, but 'find' can be restricted to a directory structure - thats about the difference I can see in a quick manpage scan.
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find",
or may other commands. billions of different option combinations, some
of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
On Sat, 14 Aug 2021 20:53:08 -0000 (UTC)
Martin Gregorie <martin@mydomain.invalid> wrote:
On Sat, 14 Aug 2021 12:57:09 -0700, Mike Easter wrote:
The commands were designed to be very powerful; the greater the powerThe other thing that needs to be taught is that each command is
the greater the 'responsibility'. Sometimes when one sees a man
result he feels like he is drowning.
designed to do one thing and to do it well, which is why there are so
*many* commands. hence the need to understand 'apropos', or better,
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
to see how to use it.
Of course, being thrown into the water and needing to swim back out.. and sadly there isn't a lot else. If the student is capable of using
is one way to learn to swim :-)
command lines on another system, then something like 'Linux in a
Nutshell' may be helpful, but that's about the only decent book I know
unless there's a 'Linux for Dummies' available and they're not put off
by the title.
If I go on amazon and search for "Linux command line" I see many books
and they tend to have high rating average. Either you don't consider
them decent or you haven't performed any such search in a long time even
just for curiosity.
Now the crunch, when I unzip these on a Linux machine, I see different bastardisations of accented characters. So, for example where the full
7zip archive when extracted shows an e acute correctly in both a console
and a file manager listing ...
"Chat Botté, Le" [e is correctly acute]
... (if you're wondering, a French children's picture book version of apparently 'Puss In Boots'), while with the WinZip main archive a
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
... and a file manager listing has a graphic character resembling a 2x2 matrix, concerning which note that while \302 octal = \xC2 hex, and
\202 octal = \x82 hex, only the second of these and not the first
appears in the symbol:
|00|
|82|
My problem is that I can't find a search term to trap this strange
character to correct it, for example the following, and a few similar
that I've tried, don't work because they don't find the directory:
mv "Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
mv Chat\ Bott\'$\'\\302\\202\'\',\ Le "Chat Botté, Le"
<sf9afk$q7c$1@dont-email.me> <sf9heo$a6v$1@dont-email.me>On 14.08.2021 at 22:52, William Unruh scribbled:
On 2021-08-14, Martin Gregorie <martin@mydomain.invalid> wrote:
apropos 'action name' | less
as an aid to finding the command they want and than
man commandname
Unfortunately man is really good for reminding someone what various
things mean, but is pretty bad at teaching anyone how to use the
command. A much much larger section for each man page with explicity
examples would go a long way to making "man" useful for newbies (and
oldies as well).
On 15/08/2021 10:51 am, Paul wrote:
Martin Gregorie wrote:
On Sat, 14 Aug 2021 22:52:08 +0000, William Unruh wrote:
Says someone, apparently, who has never looked at the commandQuite right: I don't use it because 'locate' is *much* faster and
"find", or
may other commands. billions of different option combinations, some of >>>> which work, others of which do not.
easier to use, especially if updatedb is run overnight by a cronjob
Similarly, 'apropos' is nearly as fast 'locate' since it only has to
scan the contents of /usr/share/man/* - and in addition, because its
scanning the first line of each manpage, it also matches words of
phrases describing what a program does, so often searching on a word
or phrase describing what a program does means you a suitable program
without knowing its name:
$ apropos 'free space'
e2freefrag (8) - report free space fragmentation information
xfs_spaceman (8) - show free space information about an XFS
filesystem
$ apropos 'space used'
space used: nothing appropriate.
$ apropos 'space usage'
df (1) - report file system disk space usage
du (1) - estimate file space usage
du (1p) - estimate file space usage
... and its no use complaining about how well or badly a manpage is
written: often the only way to fit would be to submit a manpage patch.
Yes, I know some Linux manpages are pretty bad. However, others
(those for bash, sort and awk to name but a few) are excellent and
most are usable.
This is why you keep a "notes" file.
find /media/somedisk -type d -exec ls -al -1 -d {} + >
directories.txt
find /media/somedisk -type f -exec ls -al -1 {} + > filelist.txt
Any time you put some effort into crafting one, you
record it for the future.
./ffmpeg -hwaccel nvdec -i "fedora.mkv" -y -acodec aac -vcodec
h264_nvenc -crf 23 "output2.mp4"
16.3x speed, 488FPS
Part of the fun is making them cryptic, so you can't understand them
later.
Paul
Why not:
find /media/somedisk -type f -ls > filelist.txt
Saves a process (or two)
I ran this in Windows 11
On 13/08/2021 20:28, Java Jive wrote:
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
then
# Do processing
fi
done < "${DATA}"
.... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
Uggghhh! The reason for this disgust will become clear shortly!
This is a follow up question about character encodings ...
Previously I have released to my family two versions of the same archive
of family documents going back to the reign of Queen Anne, some items possibly a little earlier. These documents were scanned (1o for
original scan) and then put through four possible stages of
post-processing:
2n Contrast 'normalised' using pnnorm
3t Textcleaned
4nt n followed by 3
5tn t followed by n
For each document, the best result was copied into the main archive,
while the above preprocessing stages were left in an '_all'
sub-directory structure, with five subdirectories named as above, each
of which having beneath it a directory tree mirroring the main archive.
The main version of the archive, which most family members seem to have downloaded, only included the main archive and didn't include the _all subdirectory with all the pre-processing results, the full version
included this directory. IIRC, the former was compressed by WinZip from
the archive as it existed on a Windows PC at the time, but WinZip threw
a wobbly over the size of the full archive, so for that I had to use 7zip.
Now the crunch, when I unzip these on a Linux machine, I see different bastardisations of accented characters. So, for example where the full
7zip archive when extracted shows an e acute correctly in both a console
and a file manager listing ...
"Chat Botté, Le" [e is correctly acute]
... (if you're wondering, a French children's picture book version of apparently 'Puss In Boots'), while with the WinZip main archive a
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
... and a file manager listing has a graphic character resembling a 2x2 matrix, concerning which note that while \302 octal = \xC2 hex, and
\202 octal = \x82 hex, only the second of these and not the first
appears in the symbol:
|00|
|82|
My problem is that I can't find a search term to trap this strange
character to correct it, for example the following, and a few similar
that I've tried, don't work because they don't find the directory:
mv "Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
mv Chat\ Bott\'$\'\\302\\202\'\',\ Le "Chat Botté, Le"
I could use a glob wildcard character such as '?', but currently all the filenames are within quotes, where globbing doesn't seem to work, and it would be a hell of a business removing the quotes, because many names in
the archive use many characters that would each need to be anticipated
and escaped for in an unquoted filename, such as spaces, ampersands, brackets, etc.
Can anyone suggest a sequence that will find the file, when put inside
quotes as the filename in the controlling data file mentioned previously
in the thread, so that it can just be treated like all the other lines?
As someone here suggested the data file is now stored as UTF-8 rather
than ANSI as it was formerly, and some example lines are given below in
a form for easier readability in a ng - in reality the fields are tab separated but here are separated by double spacing and have been further abbreviated to keep them from wrapping; leading symbols such as '+' and
'=' have special meanings for the program doing the work; and, yes, the commands are basically DOS commands which for Linux are translated to
their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
On Sun, 15 Aug 2021 08:37:45 +0100, Richard Kettlewell wrote:
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find",
or may other commands. billions of different option combinations, some >>>> of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
Both look for filenames, but 'find' can be restricted to a directory structure - thats about the difference I can see in a quick manpage scan.
If I did the test purely in Linux, against an NTFS file
system, who knows whether the text string display would
look just like it does on Windows. I'm not a character
set expert and cannot predict what those look like on
the Linux side.
It's unlikely at the moment, that
Linux will even mount that file system (MFTMIRR) :-/ Thanks
to Microsoft. Only Fedora could mount it without whining.
On 13/08/2021 20:28, Java Jive wrote:
I have the following lines in a shell script ...
while [ -n "${LINE}" ]
do
if [ -n "${LINE} ]
then
# Do processing
fi
done < "${DATA}"
.... and this works fine for all but two lines in the data file, which
contain accented characters. A file erroneously named with an e acute
needs to be renamed to have an e grave, and a filename containing an e
umlaut needs to be moved to a new location and given a new name.
Uggghhh! The reason for this disgust will become clear shortly!
This is a follow up question about character encodings ...
Previously I have released to my family two versions of the same archive
of family documents going back to the reign of Queen Anne, some items possibly a little earlier. These documents were scanned (1o for
original scan) and then put through four possible stages of
post-processing:
2n Contrast 'normalised' using pnnorm
3t Textcleaned
4nt n followed by 3
5tn t followed by n
For each document, the best result was copied into the main archive,
while the above preprocessing stages were left in an '_all'
sub-directory structure, with five subdirectories named as above, each
of which having beneath it a directory tree mirroring the main archive.
The main version of the archive, which most family members seem to have downloaded, only included the main archive and didn't include the _all subdirectory with all the pre-processing results, the full version
included this directory. IIRC, the former was compressed by WinZip from
the archive as it existed on a Windows PC at the time, but WinZip threw
a wobbly over the size of the full archive, so for that I had to use 7zip.
Now the crunch, when I unzip these on a Linux machine, I see different bastardisations of accented characters. So, for example where the full
7zip archive when extracted shows an e acute correctly in both a console
and a file manager listing ...
"Chat Botté, Le" [e is correctly acute]
... (if you're wondering, a French children's picture book version of apparently 'Puss In Boots'), while with the WinZip main archive a
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
... and a file manager listing has a graphic character resembling a 2x2 matrix, concerning which note that while \302 octal = \xC2 hex, and
\202 octal = \x82 hex, only the second of these and not the first
appears in the symbol:
|00|
|82|
My problem is that I can't find a search term to trap this strange
character to correct it, for example the following, and a few similar
that I've tried, don't work because they don't find the directory:
mv "Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
mv Chat\ Bott\'$\'\\302\\202\'\',\ Le "Chat Botté, Le"
I could use a glob wildcard character such as '?', but currently all the filenames are within quotes, where globbing doesn't seem to work, and it would be a hell of a business removing the quotes, because many names in
the archive use many characters that would each need to be anticipated
and escaped for in an unquoted filename, such as spaces, ampersands, brackets, etc.
Can anyone suggest a sequence that will find the file, when put inside
quotes as the filename in the controlling data file mentioned previously
in the thread, so that it can just be treated like all the other lines?
As someone here suggested the data file is now stored as UTF-8 rather
than ANSI as it was formerly, and some example lines are given below in
a form for easier readability in a ng - in reality the fields are tab separated but here are separated by double spacing and have been further abbreviated to keep them from wrapping; leading symbols such as '+' and
'=' have special meanings for the program doing the work; and, yes, the commands are basically DOS commands which for Linux are translated to
their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
On 15/08/2021 10:51 am, Paul wrote:
Martin Gregorie wrote:
On Sat, 14 Aug 2021 22:52:08 +0000, William Unruh wrote:
Says someone, apparently, who has never looked at the commandQuite right: I don't use it because 'locate' is *much* faster and
"find", or
may other commands. billions of different option combinations, some of >>>> which work, others of which do not.
easier to use, especially if updatedb is run overnight by a cronjob
Similarly, 'apropos' is nearly as fast 'locate' since it only has to
scan the contents of /usr/share/man/* - and in addition, because its
scanning the first line of each manpage, it also matches words of
phrases describing what a program does, so often searching on a word
or phrase describing what a program does means you a suitable program
without knowing its name:
$ apropos 'free space'
e2freefrag (8) - report free space fragmentation information
xfs_spaceman (8) - show free space information about an XFS
filesystem
$ apropos 'space used'
space used: nothing appropriate.
$ apropos 'space usage'
df (1) - report file system disk space usage
du (1) - estimate file space usage
du (1p) - estimate file space usage
... and its no use complaining about how well or badly a manpage is
written: often the only way to fit would be to submit a manpage patch.
Yes, I know some Linux manpages are pretty bad. However, others
(those for bash, sort and awk to name but a few) are excellent and
most are usable.
This is why you keep a "notes" file.
find /media/somedisk -type d -exec ls -al -1 -d {} + >
directories.txt
find /media/somedisk -type f -exec ls -al -1 {} + > filelist.txt
Any time you put some effort into crafting one, you
record it for the future.
./ffmpeg -hwaccel nvdec -i "fedora.mkv" -y -acodec aac -vcodec
h264_nvenc -crf 23 "output2.mp4"
16.3x speed, 488FPS
Part of the fun is making them cryptic, so you can't understand them
later.
Paul
Why not:
find /media/somedisk -type f -ls > filelist.txt
Saves a process (or two)
On Sun, 15 Aug 2021 08:37:45 +0100, Richard Kettlewell wrote:
Martin Gregorie <martin@mydomain.invalid> writes:
William Unruh wrote:
Says someone, apparently, who has never looked at the command "find",
or may other commands. billions of different option combinations, some >>>> of which work, others of which do not.
Quite right: I don't use it because 'locate' is *much* faster and
easier to use, especially if updatedb is run overnight by a cronjob
Bad comparison, since it doesn’t do the same thing.
Both look for filenames, but 'find' can be restricted to a directory structure - thats about the difference I can see in a quick manpage scan.
Il 15/08/2021 13:57, Java Jive ha scritto:
Can anyone suggest a sequence that will find the file, when put inside
quotes as the filename in the controlling data file mentioned
previously in the thread, so that it can just be treated like all the
other lines? As someone here suggested the data file is now stored as
UTF-8 rather than ANSI as it was formerly, and some example lines are
given below in a form for easier readability in a ng - in reality
the fields are tab separated but here are separated by double spacing
and have been further abbreviated to keep them from wrapping; leading
symbols such as '+' and '=' have special meanings for the program
doing the work; and, yes, the commands are basically DOS commands
which for Linux are translated to their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
Hi,
you could use the find command looking for filenames as a regular
expression, then use the command you need on them.
In this example I search for files with the extension ".o", display the
name with the command 'echo' and display it again converted to
uppercase:
find . -iregex ".*\.o$" -exec bash -c "echo -n original: {} && echo \"
modified: {}\" | tr [a-z] [A-Z]}" \;
There should be everything you need.
So, for example, this works because I'm specifying and finding the neighbouring characters of one known instance, not because ls is finding
the oddball characters directly ...
ls Chat\ Bott?,\ Le | sed 's~\xc2\x82~é~g'
... whereas these don't, with neither single nor double backslashes nor various other combinations that I've tried, because neither find nor ls
seem able to find the oddball characters directly:
find . -regex ".*\\xc2\\x82.*"
ls -R *\\xc2\\x82*
ls -R *'$'\\302\\202''*
On Mon, 16 Aug 2021 10:23:23 +0100
Java Jive <java@evij.com.invalid> wrote:
So, for example, this works because I'm specifying and finding the
neighbouring characters of one known instance, not because ls is finding
the oddball characters directly ...
ls Chat\ Bott?,\ Le | sed 's~\xc2\x82~é~g'
... whereas these don't, with neither single nor double backslashes nor
various other combinations that I've tried, because neither find nor ls
seem able to find the oddball characters directly:
find . -regex ".*\\xc2\\x82.*"
ls -R *\\xc2\\x82*
ls -R *'$'\\302\\202''*
Try ls -R *$'\302\202'*
No luck with that either ...
ls: cannot access '*'$'\302\202''*': No such file or directory
On Mon, 16 Aug 2021 15:33:15 +0100, Java Jive wrote:
No luck with that either ...Might be worth writing a noddy Java program to see if it can resolve your problem character codes.
ls: cannot access '*'$'\302\202''*': No such file or directory
The Java 'char' primitive can hold multibyte character values. and the Character() class provides methods to recognise character types, lengths,
and non-Unicode characters.
On 15/08/2021 22:27, jak wrote:
Il 15/08/2021 13:57, Java Jive ha scritto:
Can anyone suggest a sequence that will find the file, when put
inside quotes as the filename in the controlling data file mentioned
previously in the thread, so that it can just be treated like all the
other lines? As someone here suggested the data file is now stored as
UTF-8 rather than ANSI as it was formerly, and some example lines are
given below in a form for easier readability in a ng - in reality
the fields are tab separated but here are separated by double spacing
and have been further abbreviated to keep them from wrapping; leading
symbols such as '+' and '=' have special meanings for the program
doing the work; and, yes, the commands are basically DOS commands
which for Linux are translated to their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
Hi,
you could use the find command looking for filenames as a regular
expression, then use the command you need on them.
In this example I search for files with the extension ".o", display the
name with the command 'echo' and display it again converted to
uppercase:
find . -iregex ".*\.o$" -exec bash -c "echo -n original: {} && echo
\" modified: {}\" | tr [a-z] [A-Z]}" \;
There should be everything you need.
Thanks but no, that doesn't work. I had considered, before the script
works through the data file, of running a pre-process to find and rename
all these characters, but neither find nor ls will actually find the erroneous characters *DIRECTLY*. The best either can do is find the characters either side, but that means I have to know in advance where
all the problems are, and I'm not sure yet that I do. Really, if I'm
going to go down that road, I need a way of searching the entire archive structure directly for affected files and renaming them, as a separate process from working through the data file.
So, for example, this works because I'm specifying and finding the neighbouring characters of one known instance, not because ls is finding
the oddball characters directly ...
ls Chat\ Bott?,\ Le | sed 's~\xc2\x82~é~g'
... whereas these don't, with neither single nor double backslashes nor various other combinations that I've tried, because neither find nor ls
seem able to find the oddball characters directly:
find . -regex ".*\\xc2\\x82.*"
ls -R *\\xc2\\x82*
ls -R *'$'\\302\\202''*
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
So, for example, this works because I'm specifying and finding the neighbouring characters of one known instance, not because ls is finding
the oddball characters directly ...
ls Chat\ Bott?,\ Le | sed 's~\xc2\x82~é~g'
... whereas these don't, with neither single nor double backslashes nor various other combinations that I've tried, because neither find nor ls
seem able to find the oddball characters directly:
find . -regex ".*\\xc2\\x82.*"
ls -R *\\xc2\\x82*
ls -R *'$'\\302\\202''*
Java Jive wrote:
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
Are you sure the filename is exactly as you say/think? What does
ls -b
show?
On 16/08/2021 16:58, Martin Gregorie wrote:
On Mon, 16 Aug 2021 15:33:15 +0100, Java Jive wrote:
No luck with that either ...Might be worth writing a noddy Java program to see if it can resolve
ls: cannot access '*'$'\302\202''*': No such file or directory
your problem character codes.
The Java 'char' primitive can hold multibyte character values. and the
Character() class provides methods to recognise character types,
lengths,
and non-Unicode characters.
But I can't be sure that any of the target machines will have Java,
Perl, or Python installed. This has to be achieved with what will
normally be installed on a Linux or MacOS box.
Andy Burns wrote:
Java Jive wrote:
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
Are you sure the filename is exactly as you say/think? What does
ls -b
show?
Using a Perl script, I created some examples.
File "Y" is the php-failure induced problem name the OP has.
File "Z" is the visually-correct one.
https://i.postimg.cc/gksLyGFL/rename2-output.gif
So you can create your own for a test.
*********************** rename2.ps *************************
printf("this is a test\n");
$start = "Chat Bott";
$finish = ", Le";
$naughty1 = <\x{C3}\x{A9}> ;
$naughty2 = <\x{E9}> ;
On Mon, 16 Aug 2021 17:28:06 +0100, Java Jive wrote:
On 16/08/2021 16:58, Martin Gregorie wrote:
On Mon, 16 Aug 2021 15:33:15 +0100, Java Jive wrote:
No luck with that either ...Might be worth writing a noddy Java program to see if it can resolve
ls: cannot access '*'$'\302\202''*': No such file or directory
your problem character codes.
The Java 'char' primitive can hold multibyte character values. and the
Character() class provides methods to recognise character types,
lengths,
and non-Unicode characters.
But I can't be sure that any of the target machines will have Java,
Perl, or Python installed. This has to be achieved with what will
normally be installed on a Linux or MacOS box.
Does thet matter? I thought you were treating this archived article name sanitization as either a one-off activity of something that doesn't
happen regularly and, anyway that it was something that you did on your system before distributing the results round your family group.
As it happens I've just knocked up a bit of Java to see just what it can
do in the way of automated character translation, so if you'd care to
send me, martin@gregorie.org, a short file (100-500 chars max) containing
a mix of readable and non-readable example text, I'll run it through my
code.
Attaching it as a gzipped file should get it here without further
mangling.
On 16/08/2021 19:46, Paul wrote:
Andy Burns wrote:
Java Jive wrote:
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
Are you sure the filename is exactly as you say/think? What does
ls -b
show?
Thanks to you and 'jak' for suggesting this!
While still none of the following work ...
ls -R -b | grep '\xc2\x82'
ls -R -b | grep -E '\xc2\x82'
ls -R -b | grep '\uc282'
ls -R -b | grep -E '\uc282'
ls -R -b | grep '\u82c2'
ls -R -b | grep -E '\u82c2'
ls -R -b | grep '\uc282'
ls -R -b | grep -E '\uc282'
ls -R -b | grep '\u82c2'
ls -R -b | grep -E '\u82c2'
... this at least finds all the files that I'm already aware of,
suggesting that I may know about all of them ...
ls -R -b | grep -E '\\[0-7]{3}'
There are 35 files or directories at fault, nearly all are e acute, but
there a couple of e umlaut and 6 files with both an e grave and an e
acute :-(
Now I have to devise a method of renaming them, in other words of
ensuring that the mv command will find them. I've just tried the
following manual command to see what happens (it'll wrap, but originally
it was all one command-line):
OLDIFS=${IFS}; IFS=$'\n'; for A in $(ls -1Rb * | grep -E
'(:|\\302\\202)'; do if [ "S{A: -1}" == ":" ]; then export
LASTDIR="${A/:/}; else pushd "${LASTDIR}"; mv ${A/\\302\\202/?} ${A/\\302\\202/é}; popd; fi; done; unset LASTDIR; IFS=${OLDIFS}
Guess what now! The files were renamed, but the slashes that were
supposed to escape the spaces were included in the name! FFS, HOW INCONSISTENT IS THAT???!!! Why are the slashes successful in escaping
the spaces in the source name but getting included as part of the target name? Alright, so I can programme around that, but I shouldn't have to,
the illogicality of it all is just maddening!
Using a Perl script, I created some examples.
File "Y" is the php-failure induced problem name the OP has.
File "Z" is the visually-correct one.
PHP was not involved, it was WinZip that created the problem, whereas 7z
did not, but for one thing, I didn't notice at the time, and for
another, people would have had to install software to handle *.7z files, whereas the ability to handle *.zip files is native to many/most/all
modern OSs.
https://i.postimg.cc/gksLyGFL/rename2-output.gif
So you can create your own for a test.
*********************** rename2.ps *************************
printf("this is a test\n");
$start = "Chat Bott";
$finish = ", Le";
$naughty1 = <\x{C3}\x{A9}> ;
$naughty2 = <\x{E9}> ;
I think this is suffering from the same problem that all the other
approaches have had, that you're creating two characters not one. BTW,
it's hex C2, followed by hex 82.
After some further thought, I remembered about the \u regular expression syntax. Being unsure of the correct byte order, I tried both, but
neither of the following work either, whereas logically I would have
thought that one of them should:
find . -regex ".*\uc282.*"
find . -regex ".*\u82c2.*"
But at least now there's hope, see above.
Tx again to all.
Thanks to you and 'jak' for suggesting this!
While still none of the following work ...
On 16/08/2021 19:46, Paul wrote:
Andy Burns wrote:
Java Jive wrote:
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
Are you sure the filename is exactly as you say/think? What does
ls -b
show?
Thanks to you and 'jak' for suggesting this!
While still none of the following work ...
ls -R -b | grep '\xc2\x82'
ls -R -b | grep -E '\xc2\x82'
ls -R -b | grep '\uc282'
ls -R -b | grep -E '\uc282'
ls -R -b | grep '\u82c2'
ls -R -b | grep -E '\u82c2'
ls -R -b | grep '\uc282'
ls -R -b | grep -E '\uc282'
ls -R -b | grep '\u82c2'
ls -R -b | grep -E '\u82c2'
... this at least finds all the files that I'm already aware of,
suggesting that I may know about all of them ...
ls -R -b | grep -E '\\[0-7]{3}'
There are 35 files or directories at fault, nearly all are e acute, but
there a couple of e umlaut and 6 files with both an e grave and an e
acute :-(
Now I have to devise a method of renaming them, in other words of
ensuring that the mv command will find them. I've just tried the
following manual command to see what happens (it'll wrap, but originally
it was all one command-line):
OLDIFS=${IFS}; IFS=$'\n'; for A in $(ls -1Rb * | grep -E
'(:|\\302\\202)'; do if [ "S{A: -1}" == ":" ]; then export
LASTDIR="${A/:/}; else pushd "${LASTDIR}"; mv ${A/\\302\\202/?} ${A/\\302\\202/é}; popd; fi; done; unset LASTDIR; IFS=${OLDIFS}
Guess what now! The files were renamed, but the slashes that were
supposed to escape the spaces were included in the name! FFS, HOW INCONSISTENT IS THAT???!!! Why are the slashes successful in escaping
the spaces in the source name but getting included as part of the target name? Alright, so I can programme around that, but I shouldn't have to,
the illogicality of it all is just maddening!
Using a Perl script, I created some examples.
File "Y" is the php-failure induced problem name the OP has.
File "Z" is the visually-correct one.
PHP was not involved, it was WinZip that created the problem, whereas 7z
did not, but for one thing, I didn't notice at the time, and for
another, people would have had to install software to handle *.7z files, whereas the ability to handle *.zip files is native to many/most/all
modern OSs.
https://i.postimg.cc/gksLyGFL/rename2-output.gif
So you can create your own for a test.
*********************** rename2.ps *************************
printf("this is a test\n");
$start = "Chat Bott";
$finish = ", Le";
$naughty1 = <\x{C3}\x{A9}> ;
$naughty2 = <\x{E9}> ;
I think this is suffering from the same problem that all the other
approaches have had, that you're creating two characters not one. BTW,
it's hex C2, followed by hex 82.
After some further thought, I remembered about the \u regular expression syntax. Being unsure of the correct byte order, I tried both, but
neither of the following work either, whereas logically I would have
thought that one of them should:
find . -regex ".*\uc282.*"
find . -regex ".*\u82c2.*"
But at least now there's hope, see above.
Tx again to all.
Can anyone suggest a sequence that will find the file, when put inside
quotes as the filename in the controlling data file mentioned previously
in the thread, so that it can just be treated like all the other lines?
As someone here suggested the data file is now stored as UTF-8 rather
than ANSI as it was formerly, and some example lines are given below in
a form for easier readability in a ng - in reality the fields are tab separated but here are separated by double spacing and have been further abbreviated to keep them from wrapping; leading symbols such as '+' and
'=' have special meanings for the program doing the work; and, yes, the commands are basically DOS commands which for Linux are translated to
their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
On 16/08/2021 19:46, Paul wrote:
Andy Burns wrote:
Java Jive wrote:
console listing shows a very odd character sequence instead of the e
acute ...
"Chat Bott'$'\302\202'', Le"
Are you sure the filename is exactly as you say/think? What does
ls -b
show?
Thanks to you and 'jak' for suggesting this!
While still none of the following work ...
ls -R -b | grep '\xc2\x82'
ls -R -b | grep -E '\xc2\x82'
On 15/08/2021 12:57, Java Jive wrote:
Can anyone suggest a sequence that will find the file, when put inside
quotes as the filename in the controlling data file mentioned
previously in the thread, so that it can just be treated like all the
other lines? As someone here suggested the data file is now stored as
UTF-8 rather than ANSI as it was formerly, and some example lines are
given below in a form for easier readability in a ng - in reality
the fields are tab separated but here are separated by double spacing
and have been further abbreviated to keep them from wrapping; leading
symbols such as '+' and '=' have special meanings for the program
doing the work; and, yes, the commands are basically DOS commands
which for Linux are translated to their bash equivalents:
=ATTRIB -R "./F H/Close/Sts Mary & John Churchyard Monuments.pdf"
=RD "./F H /_all/1o/Blessig & Heyder"
REN "./Chat Bott'$'\302\202'', Le" "Chat Botté, Le"
MOVE "./Photo - D & M Close.png" "./Photos/D & M Close.png"
[etc]
I've completely fixed the problem with the following code inserted
before processing the data file. Thanks for all the help here that
enabled me to do this. It'll wrap of course, sorry can't help that,
beyond reducing the tabs to two spaces:
# Search for WinZip's botched accented characters
# in the main download of v1: MacFarlane-Main.zip
# 35 pathnames affected, botched characters are:
# Intended Stored incorrectly as
# Char Octal Hex
# é (acute) \302\202 \xC2\x82
# ë (diaeresis) \302\211 \xC2\x89
# è (grave) \302\212 \xC2\x8A
# Á (acute) µ
OLDIFS=${IFS} # Normally IFS=$' \t\n'
IFS=$'\n'
LASTREN=""
for A in $(ls -1bR | grep -E '(:|µ|\\[0-7]{3}\\[0-7]{3})')
do
if [ -n "${Debug}" ]
then
echo "A = \"${A}\""
fi
if [ "${A: -1}" == ":" ]
then
THISDIR="${A/:/}"
if [ "${THISDIR}" == "${LASTREN/ -> .*/}" ]
then
THISDIR="${LASTREN/.* -> /}"
fi
if [ -n "${Debug}" ]
then
echo "THISDIR = \"${THISDIR}\""
fi
else
SC="${A}"
DS="${A}"
while [ -n "$(echo \"${SC}\" | grep -E '(µ|\\[0-7]{3}\\[0-7]{3})')" ]
do
case $(echo "${SC}" | sed -E 's~^.*(µ|\\[0-7]{3}\\[0-7]{3}).*$~\1~') in
"µ") # A acute
SC="${SC//µ/?}"
DS="${DS//µ/Á}"
;;
"\302\202") # e acute
SC="${SC//\\302\\202/?}"
DS="${DS//\\302\\202/é}"
;;
"\302\211") # e diaeresis
SC="${SC//\\302\\211/?}"
DS="${DS//\\302\\211/ë}"
;;
"\302\212") # e grave
SC="${SC//\\302\\212/?}"
DS="${DS//\\302\\212/è}"
;;
esac
done
DS="${DS//\\/}"
pushd "${THISDIR}"
echo "mv ${SC} \"${DS}\""
if [ -z "${Dummy}" ]
then
mv ${SC} "${DS}"
fi
popd
# Remember rename in case it's a directory containing others
LASTREN="${THISDIR}/${A//\\ / } -> ${THISDIR}/${DS}"
if [ -n "${Debug}" ]
then
echo "LASTREN = \"${LASTREN}\""
fi
fi
done
IFS=${OLDIFS}
| Sysop: | Keyop |
|---|---|
| Location: | Huddersfield, West Yorkshire, UK |
| Users: | 546 |
| Nodes: | 16 (3 / 13) |
| Uptime: | 06:39:25 |
| Calls: | 10,388 |
| Calls today: | 3 |
| Files: | 14,061 |
| Messages: | 6,416,816 |
| Posted today: | 1 |
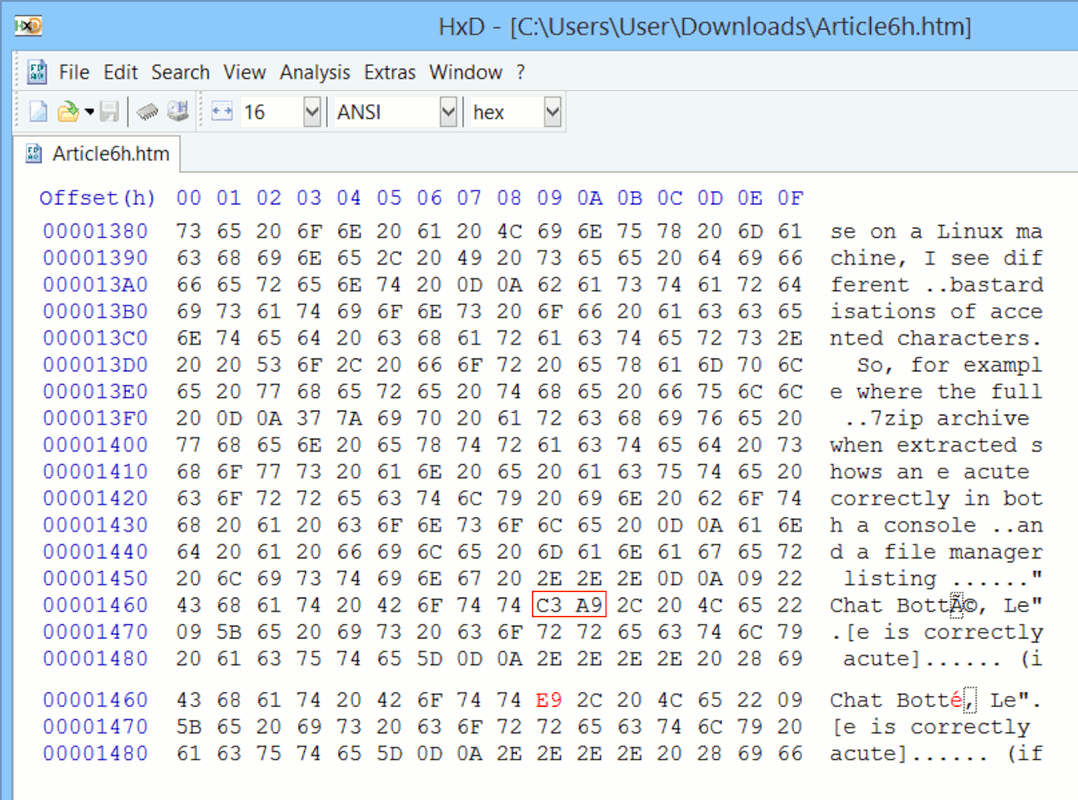{kind=link}
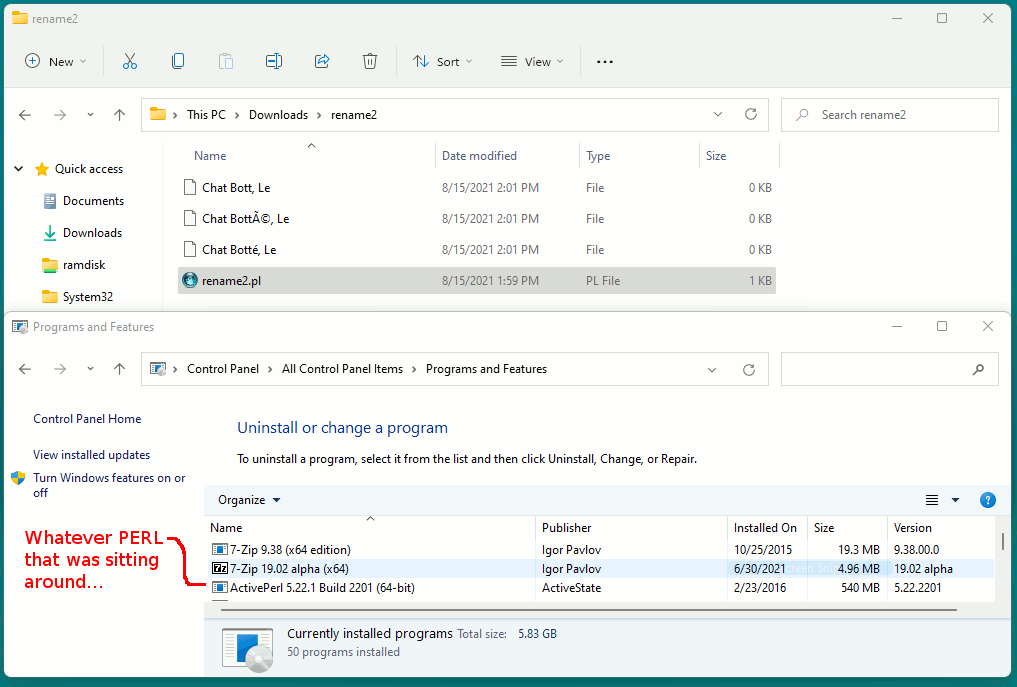{kind=link}